首页
常见问题
操作技巧
数据库
NHANES
Mimic
PIC
SicDB
Charls
GDB
数据处理
数据导入
拼接表格(数据连接/合并)
基础统计
高级统计
机器学习
Python-机器学习(SciKit Learn)
R语言机器学习(MLR3)
专题探讨
生物信息学专题
随机对照实验专题
临床实验队列专题
真实世界研究
官网链接
决策链官网
决策链网页版
决策链 Wiki
发布
发布文章
创建话题
创建版块
发布帖子
登录
注册
找回密码
首页
常见问题
操作技巧
数据库
NHANES
Mimic
PIC
SicDB
Charls
GDB
数据处理
数据导入
拼接表格(数据连接/合并)
基础统计
高级统计
机器学习
Python-机器学习(SciKit Learn)
R语言机器学习(MLR3)
专题探讨
生物信息学专题
随机对照实验专题
临床实验队列专题
真实世界研究
官网链接
决策链官网
决策链网页版
决策链 Wiki
登录
注册
找回密码
关注Bilibili官方视频号获取更多教程
进入决策链官网获取更多信息
关注决策链 (DecisionLinnc) 公众号及视频号快速获取图文教程
进入决策链Wiki获取官方使用指南
常见问题
第9页
这里汇总了用户在使用统计猿网页版和桌面版软件时遇到的常见问题与处理方法。
排序
更新
浏览
点赞
评论
Error in solve.default(denom, numr) :system is computationally singular: reciprocal condition number = 5.26589e-23
# 调查设计卡方检验
1年前
0
107
7
Error in lme.formula(as.formula(fml), data = WD, random = as.formula(fml_rand)) :nlminb problem, convergence error code = 1message = iteration limit reached without convergence (10)
# 线性混合模型
1年前
0
112
7
Error in solve.default(SKK) :system is computationally singular: reciprocal condition number = 2.16588e-21
# 协整检验
1年前
0
120
7
环境缺失:Error in library(XXXXX)
# 环境缺失
1年前
0
321
7
Error in quantile.default(WD[, var_input[i]], 0.25) :’na.rm’如果设为FALSE的话不允许有遺漏值和NaN
# 异常值过滤
1年前
0
179
7
Unterminated string. Expected delimiter: “. Path ‘GlobalDataFrameStructure.SeriesStructures
# 画布崩溃
1年前
0
162
7
Error in step(model, direction = c(method_direction)) :这个模型AIC的值是负无限的,因此’step’不能继续进行
# 逐步回归
1年前
0
98
7
自变量共线性筛查VIF:使用相关分析检查绝对相关的变量,去除相关系数为1的其中一个变量
# 自变量共线性筛查VIF
1年前
0
205
7
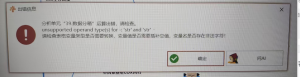
数据分箱:unsupperted operand type(s) for -:’str’ and ‘str’
# 数据分箱
1年前
0
115
7
预测器SE:Error in model_rr$predict_newdata(newdata = newdata, task = tsk_wd) : attempt to apply non-function
# 预测器SE
11个月前
0
181
7
Error: Rank deficient model matrix; insufficient data to estimate full model.Model coefficient(s) estimated as NA: cyl2:am1Likely empty cells in between-subjects design (i.e., bad data structure).
# Two-Way-ANOVA
1年前
0
127
7
转换多变量标签编码:The truth value of a Series is ambiguous. Use a.empty, a.bool(, a.item(, a.any( or a.all0).
# 转换多变量标签编码
1年前
0
94
7
数据分析描述统计:Error in `[.data.frame`(upstream_df_sub, , var_cont) :ѡ����δ�������
11个月前
0
236
7
插补:多重插补与插补空值
# 多重插补
# 插补空值
1年前
0
148
7
Error in getActiveRowSpan(estimates): Could not identify rows with actual data
# 森林图绘图错误
1年前
0
190
7
Unable to cast object of type ‘System.String’ to type ‘System.Boolean’
1年前
0
111
7
Error in imputeTS::na_ma(v, k = k, weighting = “linear”) :At least 2 non-NA data points required in the time series to apply na_ma.
# 时间序列插补
1年前
0
114
7
逻辑回归经典列线图:Error in lims[[i]]:subscript out of bounds.
11个月前
0
218
7
多分类逻辑回归:Error in relevel.factor(WD[, var dependent],ref= dep ref) :’ref’eiiee
# 多分类逻辑回归
1年前
0
120
7
限制性立方样条曲线预测图:Error in geom line(size =as.numeric(ph$gdp(“geom smooth size”)), color = ph$gdp(“geom smooth color”), : iError occurred in the 1st layer.Caused by error in ph$gdp :! $ operator is invalid for atomicvectors
11个月前
0
183
7
Error in palette(…) : Value cannot be null. (Parameter ‘s’)
# 局部多项式断点检测
# 轨迹分组趋势曲线
1年前
0
142
7
Error in binom.test(sum(mydata1[, var_input[i]] < mydata2[, var_input[i]]), :'n'必需是大于等于'x'的正整数
1年前
0
140
7
Error in lrtest.default(model_one, model_two) :’list’ object cannot be coerced to type ‘double’请检查表格变量类型是否符需要转换,变量值是否需要插补空值,变量名是否存在非法字符!
# 似然比检验
1年前
0
87
7
出现应用程序未处理的异常:OutOfMemoryException / Out of memory
# 内存
1年前
0
184
7
分组多变量轨迹模型:Error in gbmt:gbmt(x.names = var independent, unit = var dependent, time = var time,There must be at least two time points for each unit
# 分组多变量轨迹模型
11个月前
0
165
7
多重插补:Error in strsplit(var other raw,”,”);non-character argument
# 多重插补
1年前
0
186
6
Error in anova.svyglm(model_one, model_two, test = “Chisq”) :models not nested
# 似然比检验
1年前
0
110
6
机器学习多模型绘图SE:Error in str2lang(x) :
:1:2: unexpected input 1: 1_
# 机器学习SE
1年前
0
163
6
为什么机器学习交叉验证/自助法的流程只有一个Test的分析结果
# 机器学习
# 交叉验证
# 自助法
1年前
0
185
6
Error in ssum[2,,1]:subscript out of bounds
# 生存分析校准曲线
1年前
0
151
6
加载更多
热门文章
5.7W+人已阅读
发文章时怎么引用决策链?
TOP1
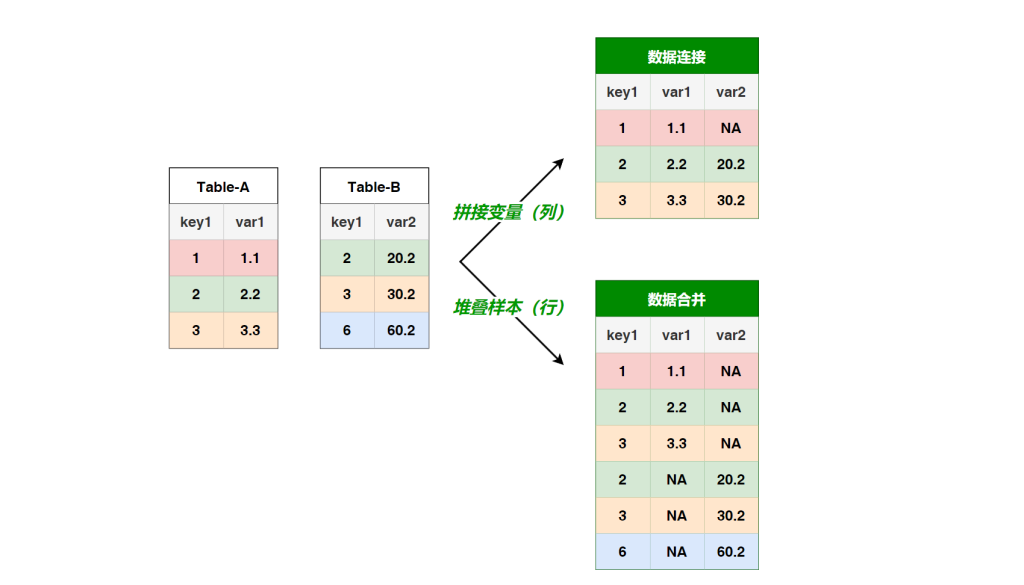
数据连接与数据合并的操作要点 -- 连接与合并之不得不说的故事
1年前
5.7W+人已阅读
TOP2
高级变量运算怎么写表达式
1年前
4.9W+人已阅读
TOP3
多条件过滤表格 转换多变量标签编码的表达式怎么写
1年前
4.9W+人已阅读
TOP4
【新手必看】软件快速上手贴(持续更新)
1年前
1.4W+人已阅读
TOP5
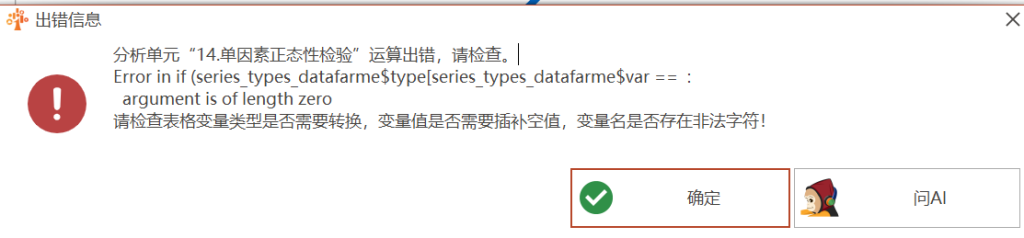
Error in if (series_types_datafarme$type[series_types_datafarme$var == : argument is of length zero
1年前
1.1W+人已阅读
TOP6
发布文章
创建话题
创建版块
发布帖子
在手机上浏览此页面
登录
没有账号?立即注册
用户名或邮箱
登录密码
记住登录
找回密码
登录
注册
已有账号,立即登录
设置用户名
设置密码
重复密码
注册





![Error in quantile.default(WD[, var_input[i]], 0.25) :'na.rm'如果设为FALSE的话不允许有遺漏值和NaN-决策链社区论坛](https://bbs.statsape.com/wp-content/uploads/2025/04/20250415160044471-62-300x52.jpg)



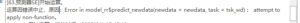







![逻辑回归经典列线图:Error in lims[[i]]:subscript out of bounds.-决策链社区论坛](https://bbs.statsape.com/wp-content/uploads/2025/08/20250821154610685-image-300x67.png)
![多分类逻辑回归:Error in relevel.factor(WD[, var dependent],ref= dep ref) :'ref'eiiee-决策链社区论坛](https://bbs.statsape.com/wp-content/uploads/2025/04/20250425215206746-image-300x55.png)


![Error in binom.test(sum(mydata1[, var_input[i]] < mydata2[, var_input[i]]), :'n'必需是大于等于'x'的正整数-决策链社区论坛](https://bbs.statsape.com/wp-content/uploads/2025/04/20250414152122184-16-300x54.jpg)






![Error in ssum[2,,1]:subscript out of bounds-决策链社区论坛](https://bbs.statsape.com/wp-content/uploads/2025/04/20250415165054322-81-300x53.jpg)