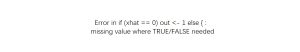首页
常见问题
操作技巧
数据库
NHANES
Mimic
PIC
SicDB
Charls
GDB
数据处理
数据导入
拼接表格(数据连接/合并)
基础统计
高级统计
机器学习
Python-机器学习(SciKit Learn)
R语言机器学习(MLR3)
专题探讨
生物信息学专题
随机对照实验专题
临床实验队列专题
真实世界研究
官网链接
决策链官网
决策链网页版
决策链 Wiki
发布
发布文章
创建话题
创建版块
发布帖子
登录
注册
找回密码
首页
常见问题
操作技巧
数据库
NHANES
Mimic
PIC
SicDB
Charls
GDB
数据处理
数据导入
拼接表格(数据连接/合并)
基础统计
高级统计
机器学习
Python-机器学习(SciKit Learn)
R语言机器学习(MLR3)
专题探讨
生物信息学专题
随机对照实验专题
临床实验队列专题
真实世界研究
官网链接
决策链官网
决策链网页版
决策链 Wiki
登录
注册
找回密码
关注Bilibili官方视频号获取更多教程
进入决策链官网获取更多信息
关注决策链 (DecisionLinnc) 公众号及视频号快速获取图文教程
进入决策链Wiki获取官方使用指南
常见问题
共321篇
这里汇总了用户在使用统计猿网页版和桌面版软件时遇到的常见问题与处理方法。
排序
更新
浏览
点赞
评论
Meta分析森林图::Error in png(tf_png, paste(plot_params$outputPath, “.png”, sep = “”), : unable to start png() device
10个月前
0
156
14
一般线性相关分析:Error in cor(WD[, final varl, method =”pearson”):’x’◆◆◆◆|◆◆
11个月前
0
173
14
限制性立方样条曲线预测图:Error in geom line(size =as.numeric(ph$gdp(“geom smooth size”)), color = ph$gdp(“geom smooth color”), : iError occurred in the 1st layer.Caused by error in ph$gdp :! $ operator is invalid for atomicvectors
11个月前
0
183
7
逻辑回归经典列线图:Error in lims[[i]]:subscript out of bounds.
11个月前
0
218
7
IDI和NRI:Error in coxph(Surv(xi, di) ~ zi) : No (non-missing) observations
11个月前
0
133
14
IDI和NRI:Error in if (pest$lDI > 0) {: missing value where TRUE/FALSE needed
# IDI和NRI
11个月前
0
168
14
SHAP解释器SE:Error in permshap.default(model rr, X= train set, feature names = xvars, : Permutation SHAP only supported for up to 14 features
# SHAP解释器SE
11个月前
0
199
13
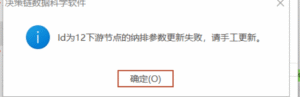
ld为X下游节点的纳排参数更新失败,请手工更新。
11个月前
0
86
12
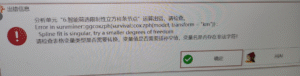
智能筛选限制性立方样条节点:Error in survminer::ggcoxzph(survival::cox.zph(model, transform = “km”)):Spline fit is singular, try a smaller degrees of freedom
# 智能筛选限制性立方样条节点
11个月前
0
182
11
Error in glm.fit(x= c(1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,:NA/NaN/lnf in ‘y’
11个月前
0
310
10
Error: input= ‘http[s]:// ‘ftp[s]://
11个月前
0
115
6
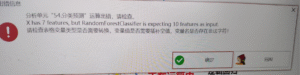
分类预测:X has 7 features, but RandomForestClassifier is expecting 10 features as input.
11个月前
0
182
12
分组多变量轨迹模型:Error in gbmt:gbmt(x.names = var independent, unit = var dependent, time = var time,There must be at least two time points for each unit
# 分组多变量轨迹模型
11个月前
0
165
7
限制性立方样条的变量节点数无法选择
11个月前
0
112
8
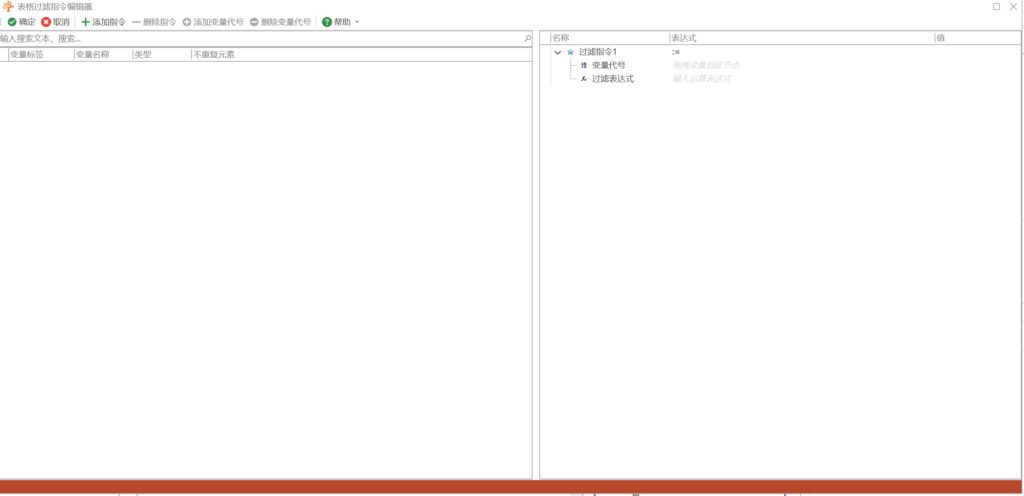
聚合表格:’NoneType’ object is not subscriptable
# 聚合表格
11个月前
0
96
11
Please convert object columns to categorical or some numeric type
11个月前
0
95
8
数据分析描述统计:Error in `[.data.frame`(upstream_df_sub, , var_cont) :ѡ����δ�������
11个月前
0
236
7
预测器SE:Error in model_rr$predict_newdata(newdata = newdata, task = tsk_wd) : attempt to apply non-function
# 预测器SE
11个月前
0
181
7
无法写入文件“/XXX”No space left on device.
12个月前
0
82
12
模型ANOVA分析:Error in Anova lll lm(mod, error, singular.ok = singular.ok, …) :there are aliased coefficients in the model
# 模型ANOVA分析
12个月前
0
134
15
辑回归多模型ROC曲线评估图:Error in names(x)<- value:'names' attribute[2] must be the same length as the vector [0]
# 辑回归多模型ROC曲线评估图
12个月前
0
118
10
孟德尔随机化:Error in if (nrow(d)== 0) return(NULL) : argument is of length zero
# 孟德尔随机化
12个月前
0
199
8
Error in if (xhat == 0) out <- 1 else { :missing value where TRUE/FALSE needed
# 模型中介效应
# 中介效应
# 双重中介效应
12个月前
0
266
15
机器学习分类模型SE:Error in .__PipeOp__train(self = self, private = private, super = super, : Assertion on ‘input to PipeOp colapply’s $train()’ failed: Must be of type ‘list’, not ‘TaskClassif/TaskSupervised/Task/R6’
# 机器学习分类模型SE
12个月前
0
143
8
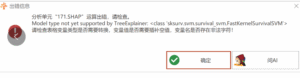
SHAP:Model type not yet supported by TreeExplainer:
# SHAP
12个月前
0
239
8
Error in if (whether cali == TRUE) {: argument is of length zero
12个月前
0
182
12
孟德尔随机化本地数据:Error: scanVcf: ‘R_Realloc’ could not re-allocate memory(87960856 bytes)
# 孟德尔随机化本地数据
12个月前
0
187
10
Error in run(param_manager) : Please enter a model name! Note that the model name needs to match the results of the data entered! Currently, the input data includes 11 entries, while the model name vector has 10 elements. Please verify that the input data and model names match appropriately, or check for any leftover data from previous loading operations.
12个月前
0
139
10
out of memoryDETAlL: Failed on request ofsize 19896550 in memory context Errorcontext
12个月前
0
96
5
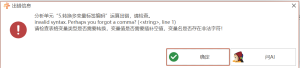
转换多变量标签编码:invalid syntax. Perhaps you forgot a comma? (
, line 1)
# 转换多变量标签编码
12个月前
0
221
8
加载更多
热门文章
5.7W+人已阅读
发文章时怎么引用决策链?
TOP1
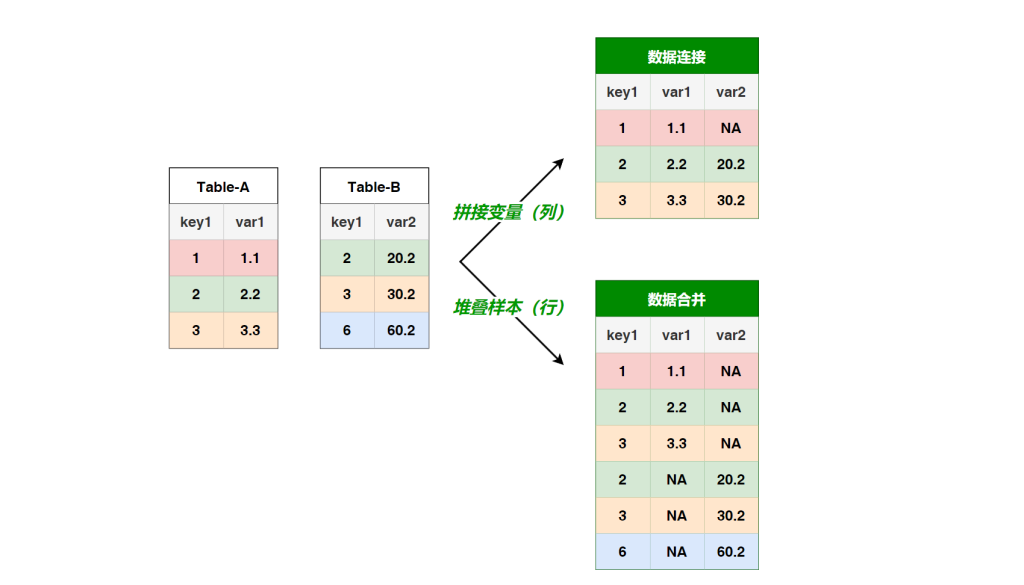
数据连接与数据合并的操作要点 -- 连接与合并之不得不说的故事
1年前
5.7W+人已阅读
TOP2
高级变量运算怎么写表达式
1年前
4.9W+人已阅读
TOP3
多条件过滤表格 转换多变量标签编码的表达式怎么写
1年前
4.9W+人已阅读
TOP4
【新手必看】软件快速上手贴(持续更新)
1年前
1.4W+人已阅读
TOP5
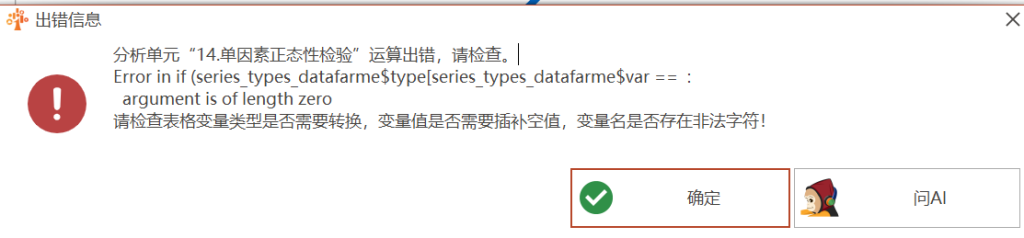
Error in if (series_types_datafarme$type[series_types_datafarme$var == : argument is of length zero
1年前
1.1W+人已阅读
TOP6
发布文章
创建话题
创建版块
发布帖子
在手机上浏览此页面
登录
没有账号?立即注册
用户名或邮箱
登录密码
记住登录
找回密码
登录
注册
已有账号,立即登录
设置用户名
设置密码
重复密码
注册




![逻辑回归经典列线图:Error in lims[[i]]:subscript out of bounds.-决策链社区论坛](https://bbs.statsape.com/wp-content/uploads/2025/08/20250821154610685-image-300x67.png)




![Error: input= 'http[s]:// 'ftp[s]://-决策链社区论坛](https://bbs.statsape.com/wp-content/uploads/2025/08/20250810115044257-image-300x63.png)




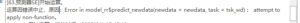

![辑回归多模型ROC曲线评估图:Error in names(x)<- value:'names' attribute[2] must be
the same length as the vector [0]-决策链社区论坛](https://bbs.statsape.com/wp-content/uploads/2025/07/20250730110853924-image-300x74.png)