首页
常见问题
操作技巧
数据库
NHANES
Mimic
PIC
SicDB
Charls
GDB
数据处理
数据导入
拼接表格(数据连接/合并)
基础统计
高级统计
机器学习
Python-机器学习(SciKit Learn)
R语言机器学习(MLR3)
专题探讨
生物信息学专题
随机对照实验专题
临床实验队列专题
真实世界研究
官网链接
决策链官网
决策链网页版
决策链 Wiki
发布
发布文章
创建话题
创建版块
发布帖子
登录
注册
找回密码
首页
常见问题
操作技巧
数据库
NHANES
Mimic
PIC
SicDB
Charls
GDB
数据处理
数据导入
拼接表格(数据连接/合并)
基础统计
高级统计
机器学习
Python-机器学习(SciKit Learn)
R语言机器学习(MLR3)
专题探讨
生物信息学专题
随机对照实验专题
临床实验队列专题
真实世界研究
官网链接
决策链官网
决策链网页版
决策链 Wiki
登录
注册
找回密码
关注Bilibili官方视频号获取更多教程
进入决策链官网获取更多信息
关注决策链 (DecisionLinnc) 公众号及视频号快速获取图文教程
进入决策链Wiki获取官方使用指南
常见问题
第2页
这里汇总了用户在使用统计猿网页版和桌面版软件时遇到的常见问题与处理方法。
排序
更新
浏览
点赞
评论
自变量共线性筛查VIF:使用相关分析检查绝对相关的变量,去除相关系数为1的其中一个变量
# 自变量共线性筛查VIF
1年前
0
205
7
SHAP解释器SE:Error in permshap.default(model rr, X= train set, feature names = xvars, : Permutation SHAP only supported for up to 14 features
# SHAP解释器SE
11个月前
0
199
13
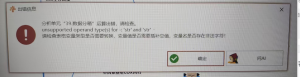
数据分箱:unsupperted operand type(s) for -:’str’ and ‘str’
# 数据分箱
1年前
0
115
7
Error in readRDS(model URl port) : ‘file’◆◆◆◆◆◆◆
# 端口连接错误
1年前
0
305
13
运算因错误中止,原因:Error in mediation::mediate(model_med, model_total, treat = var_treatment, :weights on outcome and mediator models not identical
# 模型中介效应
1年前
0
239
11
Meta偏差分析生成结果表但表中结果为空
# Meta偏差分析
1年前
0
200
14
该组数据无法绘制统计表
# KM生存曲线
1年前
0
120
5
Error in gbm.unify(model, data):Models built on data with categorical features are not supported – please encode them before training.
# SHAP解释器SE
1年前
0
216
6
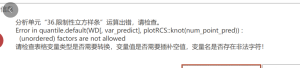
限制性立方样条:Error in quantile.default(WD[, var predictl, plotRcs::knot(num point pred)).(unordered)factors are not allowed
# 限制性立方样条
1年前
0
147
8
Error in purrr:map(var subgroups, ~TableSubgroupGLM(formula, var subgroup =. Caused by error in`.svycheck(): !..2 used in an incorrect context, no .. to look in
1年前
0
160
5
XGBoost:Invalid classes inferred from unique values of `y. Expected: [0 1], got [1 2]。
# XGBoost
1年前
0
223
11
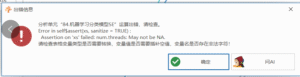
机器学习分类模型SE:Error in self$assert(xs, sanitize = TRUE) :Assertion on ‘xs’ failed: num.threads: May not be NA
# 机器学习分类模型SE
12个月前
0
107
12
Error in paste(self$Code, self$ld, sep = ” “):cannot get ALTSTRING ELT during GC
1年前
0
197
15
Error in coxph(formula = Surv(Survival_time, vital_status) ~ FOXD2.AS1 + :an id statement is required for multi-state models
# 调查设计COX回归
# cox回归
1年前
0
237
10
Error in sapply(object, “[[“, “loglik”)[2, ] :incorrect number of dimensions
# 似然比检验
1年前
0
83
15
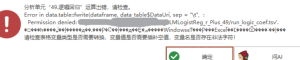
Permission denied: ‘XXXXXXXX/run logic coef.tsv’.
# 文件权限
1年前
0
180
8
Error in if (class(model)[1] != “glm” & class(model)[2] != “lm” & class(model)[1] != :missing value where TRUE/FALSE needed
# 相对超额风险分析
1年前
0
96
9
分类预测:‘DecisionTreeRegressor’ object has no attribute ‘predict proba’
# 分类预测
1年前
0
121
6
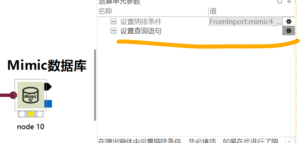
Mimic数据库:connection to server at “127.0.0.1”, port 33334 failed: Connection refused (0x0000274D/10061)Is the server runnina on that host and accepting TCP/P connections?
# Mimic数据库
12个月前
0
208
10
数据分箱:Bin edges must be unique: index([0.15, 0.19, 0.19, 0.22, 17.35], dtype=’float64′, name=’LBXlHG”)You can drop duplicate edaes by settina the ‘duplicates’ kwara
# 数据分箱
1年前
0
188
10
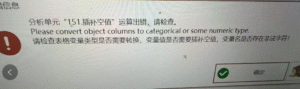
插补空值:Please convert object columns to categorical or some numeric type
1年前
0
130
5
预测器SE:Error in model_rr$predict_newdata(newdata = newdata, task = tsk_wd) : attempt to apply non-function
# 预测器SE
11个月前
0
181
7
Error in data.frame(predict(model, type = “response”), WD[, var_dependent]) :参数值意味着不同的行数: 139, 211
# 逻辑回归
1年前
0
125
26
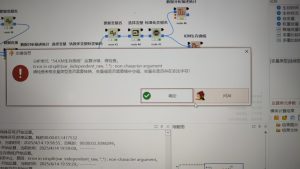
Error in strsplit(var_independent_raw, “,”) : non-character argument
1年前
0
103
13
Error in quantile.default(WD[, var_independent[i]], probs = numeric_vector) :’na.rm’如果设为FALSE的话不允许有遺漏值和NaN
# 分位数节点
1年前
0
106
13
Error: Rank deficient model matrix; insufficient data to estimate full model.Model coefficient(s) estimated as NA: cyl2:am1Likely empty cells in between-subjects design (i.e., bad data structure).
# Two-Way-ANOVA
1年前
0
127
7
Error in lme.formula(as.formula(fml), data = WD, random = as.formula(fml_rand)) :fewer observations than random effects in all level 1 groups
# 线性混合模型
1年前
0
133
8
转换多变量标签编码:The truth value of a Series is ambiguous. Use a.empty, a.bool(, a.item(, a.any( or a.all0).
# 转换多变量标签编码
1年前
0
94
7
生存分析ROC图:Error in roc.default(response, predictors[, 1], …) : ‘response’ must have two levels
1年前
0
164
14
正类问题:Error in assert binary(truth, prob = prob, positive = positive, na value = na value) Assertion on ‘positive’ failed: Must be of type ‘string’, not “integer’
# 机器学习SE
# ROC
# AUC
12个月前
0
289
13
加载更多
热门文章
5.7W+人已阅读
发文章时怎么引用决策链?
TOP1
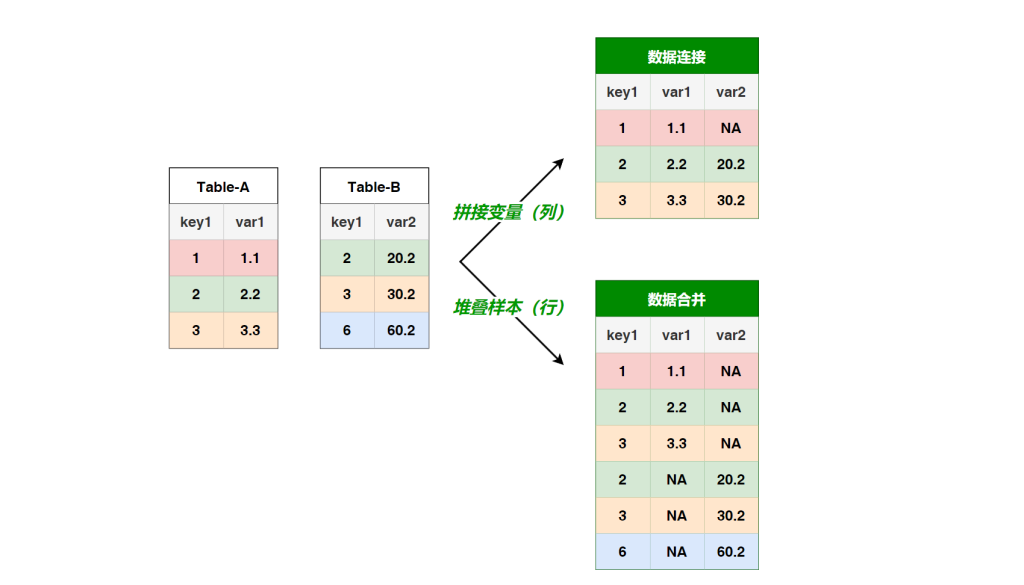
数据连接与数据合并的操作要点 -- 连接与合并之不得不说的故事
1年前
5.7W+人已阅读
TOP2
高级变量运算怎么写表达式
1年前
4.9W+人已阅读
TOP3
多条件过滤表格 转换多变量标签编码的表达式怎么写
1年前
4.9W+人已阅读
TOP4
【新手必看】软件快速上手贴(持续更新)
1年前
1.4W+人已阅读
TOP5
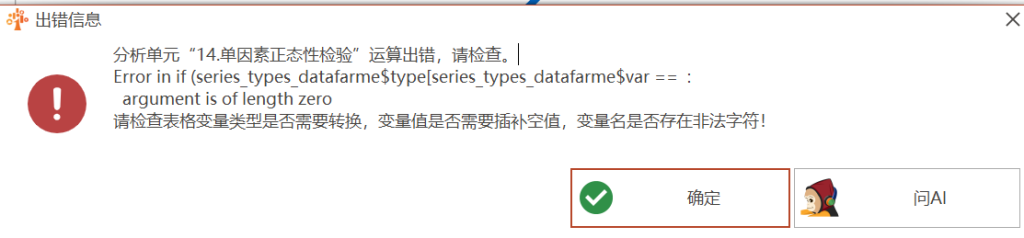
Error in if (series_types_datafarme$type[series_types_datafarme$var == : argument is of length zero
1年前
1.1W+人已阅读
TOP6
发布文章
创建话题
创建版块
发布帖子
在手机上浏览此页面
登录
没有账号?立即注册
用户名或邮箱
登录密码
记住登录
找回密码
登录
注册
已有账号,立即登录
设置用户名
设置密码
重复密码
注册









![XGBoost:Invalid classes inferred from unique values of `y. Expected: [0 1], got [1 2]。-决策链社区论坛](https://bbs.statsape.com/wp-content/uploads/2025/06/20250607142348511-image-300x69.png)



![Error in if (class(model)[1] !=](https://bbs.statsape.com/wp-content/uploads/2025/04/20250416121043426-114-300x53.jpg)

![数据分箱:Bin edges must be unique: index([0.15, 0.19, 0.19, 0.22, 17.35], dtype='float64', name='LBXlHG](https://bbs.statsape.com/wp-content/uploads/2025/05/20250513211750897-image-300x76.png)
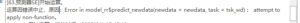

![Error in quantile.default(WD[, var_independent[i]], probs = numeric_vector) :'na.rm'如果设为FALSE的话不允许有遺漏值和NaN-决策链社区论坛](https://bbs.statsape.com/wp-content/uploads/2025/04/20250415161001714-64-300x53.jpg)



![生存分析ROC图:Error in roc.default(response, predictors[, 1], ...) : 'response' must have two levels-决策链社区论坛](https://bbs.statsape.com/wp-content/uploads/2025/05/20250501214346549-image-300x88.png)