首页
常见问题
操作技巧
数据库
NHANES
Mimic
PIC
SicDB
Charls
GDB
数据处理
数据导入
拼接表格(数据连接/合并)
基础统计
高级统计
机器学习
Python-机器学习(SciKit Learn)
R语言机器学习(MLR3)
专题探讨
生物信息学专题
随机对照实验专题
临床实验队列专题
真实世界研究
官网链接
决策链官网
决策链网页版
决策链 Wiki
发布
发布文章
创建话题
创建版块
发布帖子
登录
注册
找回密码
首页
常见问题
操作技巧
数据库
NHANES
Mimic
PIC
SicDB
Charls
GDB
数据处理
数据导入
拼接表格(数据连接/合并)
基础统计
高级统计
机器学习
Python-机器学习(SciKit Learn)
R语言机器学习(MLR3)
专题探讨
生物信息学专题
随机对照实验专题
临床实验队列专题
真实世界研究
官网链接
决策链官网
决策链网页版
决策链 Wiki
登录
注册
找回密码
关注Bilibili官方视频号获取更多教程
进入决策链官网获取更多信息
关注决策链 (DecisionLinnc) 公众号及视频号快速获取图文教程
进入决策链Wiki获取官方使用指南
常见问题
第7页
这里汇总了用户在使用统计猿网页版和桌面版软件时遇到的常见问题与处理方法。
排序
更新
浏览
点赞
评论
多条件过滤表格:invalid character’‘'(U+2018)(
,line 1)
# 多条件过滤表格
1年前
0
135
10
Error in mediation::mediate(model_med, model_total, treat = var_treatment, :number of observations do not match between mediator and outcome models
# 模型中介效应
1年前
0
135
8
Error in model_rr$predict_newdata(newdata = newdata, task = tsk_wd) :attempt to apply non-function
# 预测器SE
1年前
0
135
11
“value” parameter must be a scalar, dict or Series, but you passed a “Dataframe’
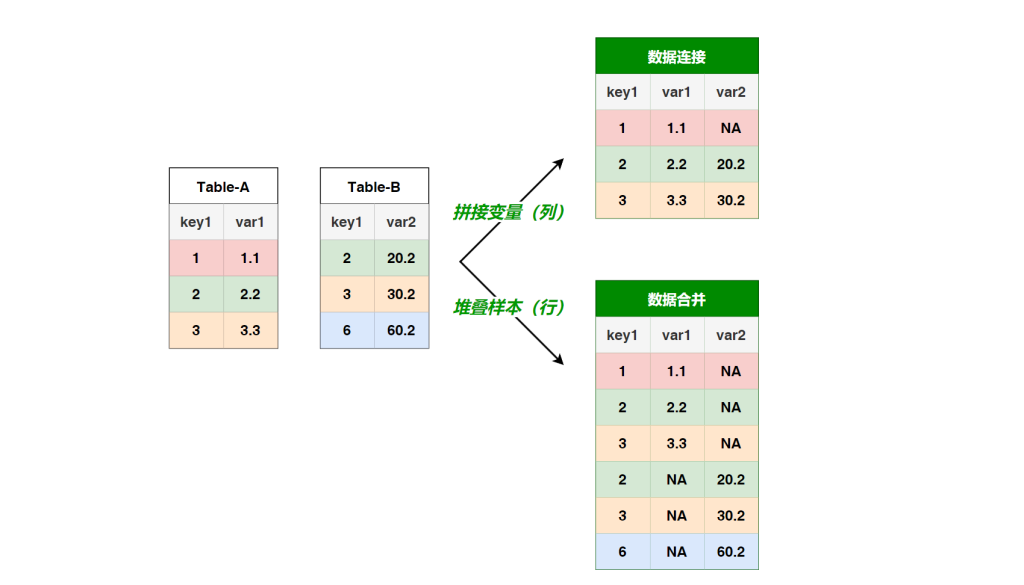
# 数据连接
1年前
0
134
10
Error in num point[[ind pred]]: attempt to select less thanone element in get1index.
# 限制性立方样条
1年前
0
134
6
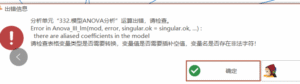
模型ANOVA分析:Error in Anova lll lm(mod, error, singular.ok = singular.ok, …) :there are aliased coefficients in the model
# 模型ANOVA分析
12个月前
0
134
15
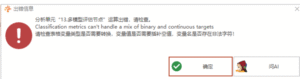
多模型评估节点:Classification metrics can’t handle a mix of binary and continuous targets
# 多模型评估节点
1年前
0
134
5
NR曲线图:Error in findrow(fit, times, extend) : no points selected for one or more curves, consider using the extend argument
1年前
0
134
9
Error in lme.formula(as.formula(fml), data = WD, random = as.formula(fml_rand)) :fewer observations than random effects in all level 1 groups
# 线性混合模型
1年前
0
133
8
IDI和NRI:Error in coxph(Surv(xi, di) ~ zi) : No (non-missing) observations
11个月前
0
133
14
选择变量:[‘subject_id’, ‘stay_id’] not in index
# 选择变量
1年前
0
133
6
Error in rms::Predict(model, origen_contin, fun = exp, ref.zero = TRUE, :predictors(s) not in model: origen_contin
# 限制性立方样条
1年前
0
132
12
Error in coxfit$u %*% var :non-conformable arguments
# 分位交互回归分析
1年前
0
132
10
SHAP:expected str, bytes or os.PathLike object, not NoneType
# SHAP
1年前
0
131
11
机器学习多模型绘图SE:Error in str2lang(x):
:1:2: unexpected input1:1_ ^
# 机器学习多模型绘图SE
1年前
0
131
12
多分类逻辑回归:Error in MASS:polr(as.formula(fml), weights = WD[, var weight], data = WD, :attempt to find suitable starting values failed
# 多分类逻辑回归
1年前
0
130
6
Error in lda(x, y, reduced_rank, k) : rank out of bounds
# 降秩回归
1年前
0
130
8
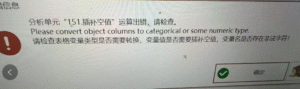
插补空值:Please convert object columns to categorical or some numeric type
1年前
0
130
5
Error in Summary.factor(c(1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L,:sum’ not meaningful for factors
# 调查设计卡方检验
1年前
0
130
13
多分类Rcs曲线图:Error in’l,data.frame`(cbind dataframe,,xvar datal): wo00080000009。
# 多分类Rcs曲线图
1年前
0
130
13
报告中表格显示不全
1年前
0
130
8
RuntimeBinderException Cannot implicitly convert type ‘Python.Runtime.PyObject’ to ‘string[]’
1年前
0
129
13
Error in validate_param_range(pm$get para value(“maxdepth”),maxdepth”,lues is required! for theNote, for automatic parameter tuning, a reasonable range of vmaxdepth parameter, input 200,300
# 机器学习SE
1年前
0
129
8
Error in nls(y ~ 1/(1 + exp((xmid – x)/scal)), data = xy, start = list(xmid = aux[[1L]], :算法的步因素0.000488281的大小被减少到小于0.000976562的’minFactor’值。 Error in nls(y ~ 1/(1 + exp((xmid – x)/scal)), data = xy, start = list(xmid = aux[[1L]], :奇异梯度。 Error in numericDeriv(form[[3L]], names(ind), env, central = nDcentral) :在计算模型的时候产生了缺省值或无限值。 Error in qr.solve(QR.B, cc) : solve里的’a’是奇异矩阵。 Error in nls(y ~ 1/(1 + exp((xmid – x)/scal)), data = xy, start = list(xmid = aux[[1L]], :循环次数超过了50这个最大值。
# 逻辑斯蒂生长曲线模型
1年前
0
129
14
运算因错误中止,原因:Error in stopIfNotConsistent(result, “relative.effect”) :Can only apply relative.effect to models of the following types: consistency, regression
# 贝叶斯Network联赛表
1年前
0
129
10
Error in if (any(y < 0)) stop("negative values not allowed for the 'Poisson' family") :missing value where TRUE/FALSE needed
# 单因素回归-泊松分布
1年前
0
128
10
Error: Rank deficient model matrix; insufficient data to estimate full model.Model coefficient(s) estimated as NA: cyl2:am1Likely empty cells in between-subjects design (i.e., bad data structure).
# Two-Way-ANOVA
1年前
0
127
7
Error in UseMethod(“predict”) :no applicable method for ‘predict’ applied to an object of class “c(‘gamm’, ‘list’)”
# 回归模型预测
1年前
0
127
11
Cox_CiC曲线图:Error in decision_curve(formula_data, data = input_data, family = binomial(link = “logit”), : outcome variable is not binary (it does not take two unique values).
1年前
0
127
10
Error in array(x, c(length(x), 1L), if (!is.null(names(x))) list(names(x), :’data’ must be of a vector type, was ‘NULL’
# Meta剂量效应分析
1年前
0
127
12
加载更多
热门文章
5.7W+人已阅读
发文章时怎么引用决策链?
TOP1
数据连接与数据合并的操作要点 -- 连接与合并之不得不说的故事
1年前
5.7W+人已阅读
TOP2
高级变量运算怎么写表达式
1年前
4.9W+人已阅读
TOP3
多条件过滤表格 转换多变量标签编码的表达式怎么写
1年前
4.9W+人已阅读
TOP4
【新手必看】软件快速上手贴(持续更新)
1年前
1.4W+人已阅读
TOP5
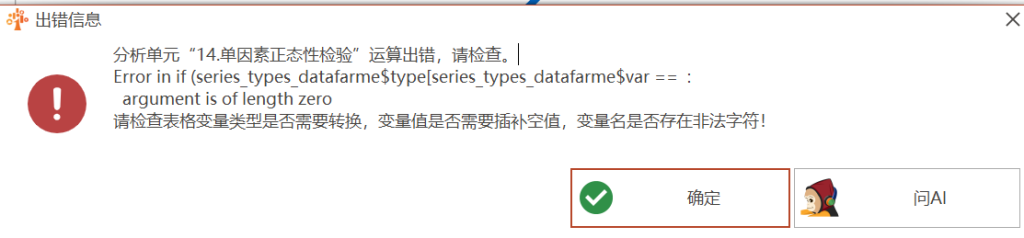
Error in if (series_types_datafarme$type[series_types_datafarme$var == : argument is of length zero
1年前
1.1W+人已阅读
TOP6
发布文章
创建话题
创建版块
发布帖子
在手机上浏览此页面
登录
没有账号?立即注册
用户名或邮箱
登录密码
记住登录
找回密码
登录
注册
已有账号,立即登录
设置用户名
设置密码
重复密码
注册





![Error in num point[[ind pred]]: attempt to select less thanone element in get1index.-决策链社区论坛](https://bbs.statsape.com/wp-content/uploads/2025/04/20250416135411726-122-300x52.jpg)



![选择变量:['subject_id', 'stay_id'] not in index-决策链社区论坛](https://bbs.statsape.com/wp-content/uploads/2025/05/20250525205725654-image-300x68.png)




![多分类逻辑回归:Error in MASS:polr(as.formula(fml), weights = WD[, var weight], data = WD, :attempt to find suitable starting values failed-决策链社区论坛](https://bbs.statsape.com/wp-content/uploads/2025/04/20250412181243200-image-300x53.png)


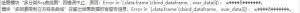

![RuntimeBinderException
Cannot implicitly convert type 'Python.Runtime.PyObject' to 'string[]'-决策链社区论坛](https://bbs.statsape.com/wp-content/uploads/2025/06/20250614212041411-image-300x112.png)

![Error in nls(y ~ 1/(1 + exp((xmid - x)/scal)), data = xy, start = list(xmid = aux[[1L]], :算法的步因素0.000488281的大小被减少到小于0.000976562的'minFactor'值。 Error in nls(y ~ 1/(1 + exp((xmid - x)/scal)), data = xy, start = list(xmid = aux[[1L]], :奇异梯度。 Error in numericDeriv(form[[3L]], names(ind), env, central = nDcentral) :在计算模型的时候产生了缺省值或无限值。 Error in qr.solve(QR.B, cc) : solve里的'a'是奇异矩阵。 Error in nls(y ~ 1/(1 + exp((xmid - x)/scal)), data = xy, start = list(xmid = aux[[1L]], :循环次数超过了50这个最大值。-决策链社区论坛](https://bbs.statsape.com/wp-content/uploads/2025/04/20250416121505575-116-300x136.jpg)