首页
常见问题
操作技巧
数据库
NHANES
Mimic
PIC
SicDB
Charls
GDB
数据处理
数据导入
拼接表格(数据连接/合并)
基础统计
高级统计
机器学习
Python-机器学习(SciKit Learn)
R语言机器学习(MLR3)
专题探讨
生物信息学专题
随机对照实验专题
临床实验队列专题
真实世界研究
官网链接
决策链官网
决策链网页版
决策链 Wiki
发布
发布文章
创建话题
创建版块
发布帖子
登录
注册
找回密码
首页
常见问题
操作技巧
数据库
NHANES
Mimic
PIC
SicDB
Charls
GDB
数据处理
数据导入
拼接表格(数据连接/合并)
基础统计
高级统计
机器学习
Python-机器学习(SciKit Learn)
R语言机器学习(MLR3)
专题探讨
生物信息学专题
随机对照实验专题
临床实验队列专题
真实世界研究
官网链接
决策链官网
决策链网页版
决策链 Wiki
登录
注册
找回密码
关注Bilibili官方视频号获取更多教程
进入决策链官网获取更多信息
关注决策链 (DecisionLinnc) 公众号及视频号快速获取图文教程
进入决策链Wiki获取官方使用指南
常见问题
第6页
这里汇总了用户在使用统计猿网页版和桌面版软件时遇到的常见问题与处理方法。
排序
更新
浏览
点赞
评论
Error in matchit(as.formula(formu), data = table.unmatched, method = inner_method, :请检查表格变量类型是否符需要转换,变量值是否需要插补空值,变量名是否存在非法字符!
# 倾向性评分匹配
1年前
0
237
12
调查设计秩和检验:Error in if (length(unique ind) == 2 || !is.na(model[“estimate”]][[“difference in mean rank score”])) {:missing value where TRUE/FALSE needed
# 调查设计秩和检验
1年前
0
118
14
倾向性评分匹配:Error in mnps.fast(formula = formula, data = data, n.trees = nrounds,The treatment variable must be a factor variable with at least 3 levels
# 倾向性评分匹配
1年前
0
151
10
Lapack routine dgesv: system is exactly singular: U[1,1]= 0
1年前
0
270
6
转换变量类型:变量XXX类型转换失败,could not convert string to float: XXXX
# 转换变量类型
1年前
0
181
5
Mimic数据提取:Exception while reading from stream
# Mimic数据库
1年前
0
281
5
COX回归PH检验:Error in gzfile(file,”rb”): cannot open the connection
# PH检验
1年前
0
122
11
Error in eval(family$initialize) : y值必需满足0 <= y <= 1
# 逻辑回归
# 单因素线性回归
1年前
0
310
15
预测器SE:Error: Measure ’classif.acc‘ incompatible with task type ‘sury‘
# 模型预测
1年前
0
147
14
数据连接:Unable to allocate XXX GiB for an array with shape (XXXXX) and data type float64.
# 数据连接
1年前
0
173
6
分类预测:‘DecisionTreeRegressor’ object has no attribute ‘predict proba’
# 分类预测
1年前
0
121
6
Error in X %*% rowSums(cf) : non-conformable arguments
# 机器学习生存模型SE
1年前
0
160
15
Error in palette(…) : Value cannot be null. (Parameter ‘s’)
# 局部多项式断点检测
# 轨迹分组趋势曲线
1年前
0
142
7
Error in chol.default(crossprod(x)) :the leading minor of order 3 is not positive definite Error in rdrobust::rdrobust(y = WD[, var_dependent], x = WD[, var_independent[i]], :
# 局部多项式断点检测
1年前
0
167
15
Error in rdrobust::rdbwselect(y = WD[, var_dependent], x = WD[, var_independent[i]], :
# 选择断点模型
1年前
0
95
10
Error in min(i):invalid ‘type'(list) of argument
# 联合模型回归预测
1年前
0
176
6
3 nodes produced errors;, first error: matrix multiplication: incompatible matrix dimensions:5595×2 and 4×1
# 贝叶斯联合模型
1年前
0
162
14
Error in gbmt::gbmt(x.names = var_independent, unit = var_dependent, time = var_time, :Unit ‘5’ has duplicated time points
# 分组多变量轨迹模型
1年前
0
138
11
=", ">"), ret.second(split_index), :Unknown decision_type-决策链社区论坛" class="lazyload fit-cover radius8">
Error in ifelse(decision_type %in% c(“>=”, “>”), ret.second(split_index), :Unknown decision_type
# SHAP解释器SE
1年前
0
176
15
Error: You should have at least two distinct break values. Value cannot be null. (Parameter ‘s’)
# SHAP解释器SE
1年前
0
171
14
Error in gbm.unify(model, data):Models built on data with categorical features are not supported – please encode them before training.
# SHAP解释器SE
1年前
0
216
6
Error in confusionMatrix,default(as.factor(y pred label)reference = as.factorly label): The data must contain some levels that overlap the reference…
# 机器学习多模型绘图SE
# 机器学习绘图SE
1年前
0
117
14
Input y contains infinity or a value too large for dtype(‘float64’)
# 梯度提升-生存
1年前
0
167
5
Error in gbm.fit(x = x, y = y, offset = offset, distribution = distribution, :The data set is too small or the subsampling rate is too large: nTrain * bag.fraction <= n.minobsinnode
# 机器学习分类模型SE
# 机器学习回归模型SE
1年前
0
135
8
Error in ranger::ranger(dependent.variable.name = task$target_names, data = task$data(), :User interrupt or internal error.
# 机器学习分类模型SE
# 机器学习回归模型SE
1年前
0
121
5
Error in coxfit$u %*% var :non-conformable arguments
# 分位交互回归分析
1年前
0
132
10
invalid entry 0 in condlist: should be boolean ndarray
# 转换多变量标签编码
1年前
0
137
6
Error in imputeTS::na_ma(v, k = k, weighting = “linear”) :At least 2 non-NA data points required in the time series to apply na_ma.
# 时间序列插补
1年前
0
114
7
Error in tvROC.jm(joint_model, newdata = source_df, Tstart = T_start, :there are no data on subjects who had an observed event time after Tstart and longitudinal measurements before Tstart.
# 联合模型准确性评估
1年前
0
142
12
Error in lme.formula(as.formula(fml), data = WD, random = as.formula(fml_rand)) :fewer observations than random effects in all level 1 groups
# 线性混合模型
1年前
0
133
8
加载更多
热门文章
5.7W+人已阅读
发文章时怎么引用决策链?
TOP1
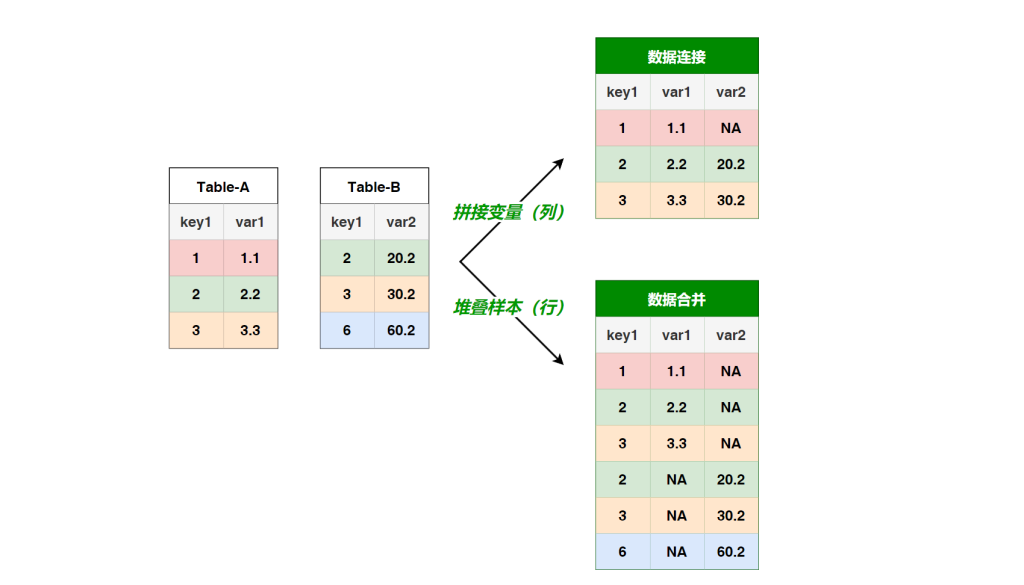
数据连接与数据合并的操作要点 -- 连接与合并之不得不说的故事
1年前
5.7W+人已阅读
TOP2
高级变量运算怎么写表达式
1年前
4.9W+人已阅读
TOP3
多条件过滤表格 转换多变量标签编码的表达式怎么写
1年前
4.9W+人已阅读
TOP4
【新手必看】软件快速上手贴(持续更新)
1年前
1.4W+人已阅读
TOP5
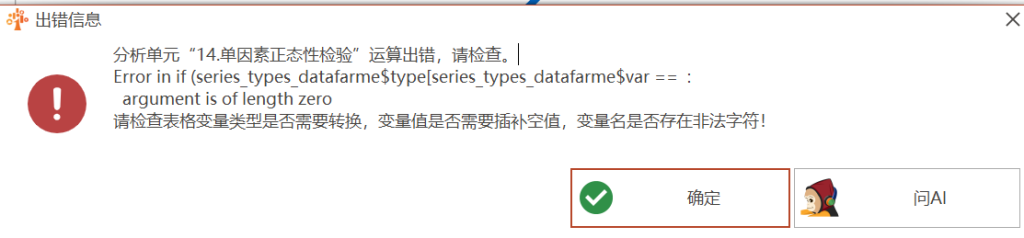
Error in if (series_types_datafarme$type[series_types_datafarme$var == : argument is of length zero
1年前
1.1W+人已阅读
TOP6
发布文章
创建话题
创建版块
发布帖子
在手机上浏览此页面
登录
没有账号?立即注册
用户名或邮箱
登录密码
记住登录
找回密码
登录
注册
已有账号,立即登录
设置用户名
设置密码
重复密码
注册




![Lapack routine dgesv: system is exactly singular: U[1,1]= 0-决策链社区论坛](https://bbs.statsape.com/wp-content/uploads/2025/04/20250413220533314-image-300x43.png)









![Error in chol.default(crossprod(x)) :the leading minor of order 3 is not positive definite Error in rdrobust::rdrobust(y = WD[, var_dependent], x = WD[, var_independent[i]], :-决策链社区论坛](https://bbs.statsape.com/wp-content/uploads/2025/04/20250416150206155-149-300x75.jpg)
![Error in rdrobust::rdbwselect(y = WD[, var_dependent], x = WD[, var_independent[i]], :-决策链社区论坛](https://bbs.statsape.com/wp-content/uploads/2025/04/20250416150049670-148-300x53.jpg)



 =", ">"), ret.second(split_index), :Unknown decision_type-决策链社区论坛" class="lazyload fit-cover radius8">
=", ">"), ret.second(split_index), :Unknown decision_type-决策链社区论坛" class="lazyload fit-cover radius8">