首页
常见问题
操作技巧
数据库
NHANES
Mimic
PIC
SicDB
Charls
GDB
数据处理
数据导入
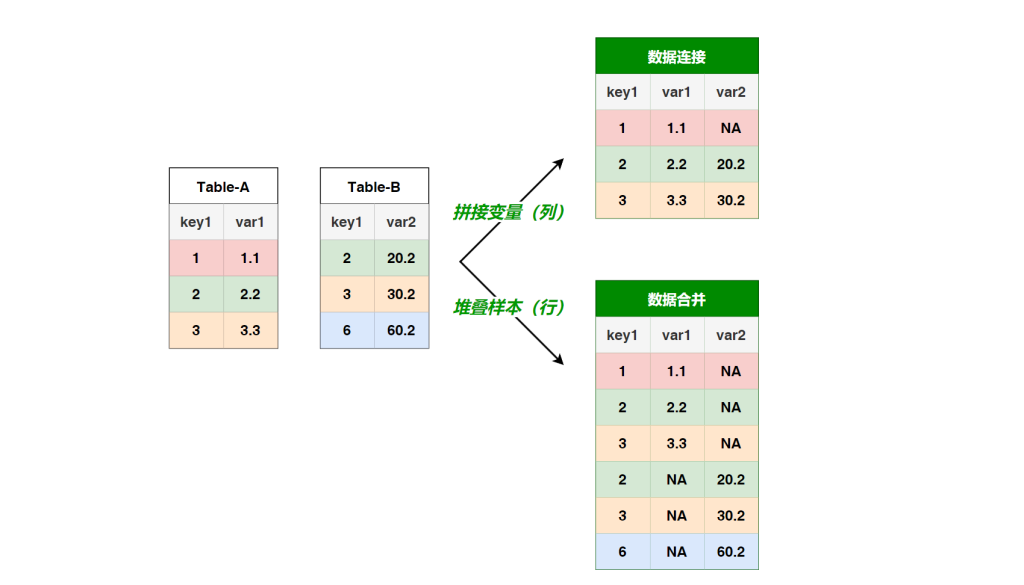
拼接表格(数据连接/合并)
基础统计
高级统计
机器学习
Python-机器学习(SciKit Learn)
R语言机器学习(MLR3)
专题探讨
生物信息学专题
随机对照实验专题
临床实验队列专题
真实世界研究
官网链接
决策链官网
决策链网页版
决策链 Wiki
发布
发布文章
创建话题
创建版块
发布帖子
登录
注册
找回密码
首页
常见问题
操作技巧
数据库
NHANES
Mimic
PIC
SicDB
Charls
GDB
数据处理
数据导入
拼接表格(数据连接/合并)
基础统计
高级统计
机器学习
Python-机器学习(SciKit Learn)
R语言机器学习(MLR3)
专题探讨
生物信息学专题
随机对照实验专题
临床实验队列专题
真实世界研究
官网链接
决策链官网
决策链网页版
决策链 Wiki
登录
注册
找回密码
关注Bilibili官方视频号获取更多教程
进入决策链官网获取更多信息
关注决策链 (DecisionLinnc) 公众号及视频号快速获取图文教程
进入决策链Wiki获取官方使用指南
常见问题
第4页
这里汇总了用户在使用统计猿网页版和桌面版软件时遇到的常见问题与处理方法。
排序
更新
浏览
点赞
评论
限制性立方样条:Error: The number of knots must be strictly between 3 and 7.
# 限制性立方样条
1年前
0
217
11
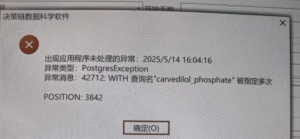
Mimic: 异常类型:PostgresExceptidm 异常消息:42712: WITH 查询名”carvedilol phosphate”被指定多次
# 药物信息
1年前
0
152
14
批量去除连锁不平衡:Error in file(file, “rt”): cannot open the connection
# 连锁不平衡
1年前
0
177
14
NHANES读取Alpha:E:\NHANES\NHANESW2007-2008\Examination\bmx e.xpt表中缺少SEQN列!不能和其他表进行联合查询,你可以尝试单是名独提取此数据集。
# NHANES读取
1年前
0
201
13
递归消除法:worker initialization failed: package or namespace load failed for ‘caret’.object ‘recvData’ is not exported by’namespace:parallel’
# 递归消除法
1年前
0
177
14
数据分箱:Bin edges must be unique: index([0.15, 0.19, 0.19, 0.22, 17.35], dtype=’float64′, name=’LBXlHG”)You can drop duplicate edaes by settina the ‘duplicates’ kwara
# 数据分箱
1年前
0
188
10
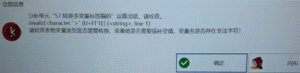
转换多变量标签编码:invalid character ‘>'(U+FF1E)(
, line 1)
# 转换多变量标签编码
1年前
0
187
11
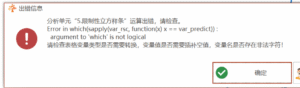
限制性立方样条:Error in which(sapply(var rsc, function(x)x== var predict))argument to ‘which’ is not logical
# 限制性立方样条
1年前
0
186
13
分类预测:model dataset compatibility.cpp:81: Atposition 3 should be feature with name APACHE2 (found BZD)
# 分类预测
1年前
0
83
8
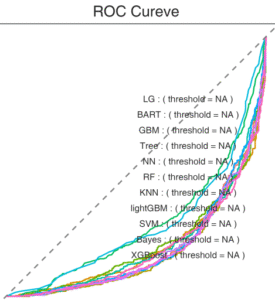
机器学习SE的ROC曲线反向,如何修正?
# 机器学习SE
1年前
0
269
14
机器学习多模型绘图SE:Error in str2lang(x) :
:1:2: unexpected input 1: 1_
# 机器学习SE
1年前
0
162
6
出现应用程序未处理的异常:OutOfMemoryException / Out of memory
# 内存
1年前
0
184
7
多分类Rcs曲线图:data.frame(x=median x data,y= max up data, label =finally text data): ⧫⧫⧫⧫⧫⧫ζ@⧫⧫⧫⧫⧫⧫:2,0
# 多分类Rcs曲线图
1年前
0
105
9
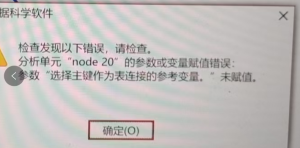
分析单元“node 20”的参数或变量赋值错误:参数“选择主键作为表连接的参考变量。”未赋值。
# 数据连接
1年前
0
113
9
高级变量运算:invalid decimal literal (
,line 1)
1年前
0
142
11
Error in purrr:map(var subgroups, ~TableSubgroupGLM(formula, var subgroup =. Caused by error in`.svycheck(): !..2 used in an incorrect context, no .. to look in
1年前
0
160
5
机器学习多横型绘图SE:Error in loadNamespace(x) : ◆◆◆◆◆`yardstick’◆◆◆◆◆
# 机器学习多横型绘图SE
1年前
0
155
10
Error in Summary.factor(c(1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L,:sum’ not meaningful for factors
# 调查设计卡方检验
1年前
0
130
13
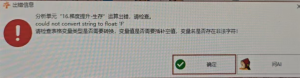
梯度提升-生存:could not convert string to float: ‘F’
# 梯度提升-生存
1年前
0
154
11
单因素亚组COX回归:Error in rowSums(fit$influencel, 1:3]): X◆◆◆◆◆◆◆y◆◆◆◆◆◆α◆◆◆。
# 单因素亚组COX回归
1年前
0
169
6
单因素亚组GLM回归:Error in purrr:map(var subgroups, ~TableSubgroupGLM(formula, var subgroup = Caused by error in TableSubgroupGLM):var suoaroup must categorica .
1年前
0
161
5
矩阵相关分析:Error in rcorr(mat one,mat two,type = method test): must have >4 observations。
# 相关分析
1年前
0
141
8
多因素正态性检验:Error in data[complete.cases(data), ] : incorrect number of dimensions
# 多因素正态性检验
1年前
0
125
13
在回归分析中,如何修改分类变量的参照/参考/ref因子
1年前
0
342
7
Cox_CiC曲线图:Error in decision_curve(formula_data, data = input_data, family = binomial(link = “logit”), : outcome variable is not binary (it does not take two unique values).
1年前
0
127
10
NR曲线图:Error in findrow(fit, times, extend) : no points selected for one or more curves, consider using the extend argument
1年前
0
134
9
生存分析ROC图:Error in roc.default(response, predictors[, 1], …) : ‘response’ must have two levels
1年前
0
164
14
Error in validate_param_range(pm$get para value(“maxdepth”),maxdepth”,lues is required! for theNote, for automatic parameter tuning, a reasonable range of vmaxdepth parameter, input 200,300
# 机器学习SE
1年前
0
129
8
Unterminated string. Expected delimiter: “. Path ‘GlobalDataFrameStructure.SeriesStructures
# 画布崩溃
1年前
0
162
7
The process cannot access the file ‘D:\XXXXXXXX.tsv’ because it is being used by another process
1年前
0
64
12
加载更多
热门文章
5.7W+人已阅读
发文章时怎么引用决策链?
TOP1
数据连接与数据合并的操作要点 -- 连接与合并之不得不说的故事
1年前
5.7W+人已阅读
TOP2
高级变量运算怎么写表达式
1年前
4.9W+人已阅读
TOP3
多条件过滤表格 转换多变量标签编码的表达式怎么写
1年前
4.9W+人已阅读
TOP4
【新手必看】软件快速上手贴(持续更新)
1年前
1.4W+人已阅读
TOP5
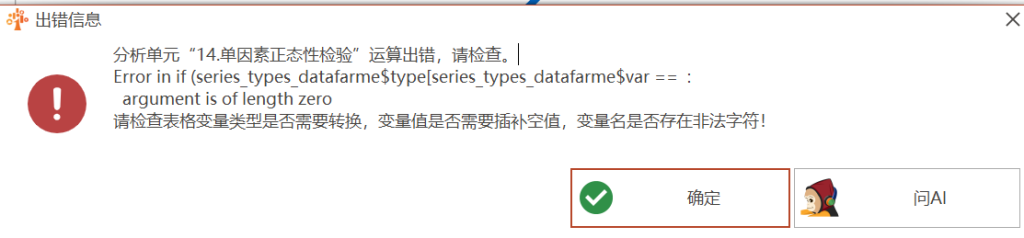
Error in if (series_types_datafarme$type[series_types_datafarme$var == : argument is of length zero
1年前
1.1W+人已阅读
TOP6
发布文章
创建话题
创建版块
发布帖子
在手机上浏览此页面
登录
没有账号?立即注册
用户名或邮箱
登录密码
记住登录
找回密码
登录
注册
已有账号,立即登录
设置用户名
设置密码
重复密码
注册





![数据分箱:Bin edges must be unique: index([0.15, 0.19, 0.19, 0.22, 17.35], dtype='float64', name='LBXlHG](https://bbs.statsape.com/wp-content/uploads/2025/05/20250513211750897-image-300x76.png)








![单因素亚组COX回归:Error in rowSums(fit$influencel, 1:3]):
X◆◆◆◆◆◆◆y◆◆◆◆◆◆α◆◆◆。-决策链社区论坛](https://bbs.statsape.com/wp-content/uploads/2025/05/20250504172215248-image-300x72.png)


![多因素正态性检验:Error in data[complete.cases(data), ] : incorrect number of dimensions-决策链社区论坛](https://bbs.statsape.com/wp-content/uploads/2025/05/20250502230828104-image-300x65.png)


![生存分析ROC图:Error in roc.default(response, predictors[, 1], ...) : 'response' must have two levels-决策链社区论坛](https://bbs.statsape.com/wp-content/uploads/2025/05/20250501214346549-image-300x88.png)