





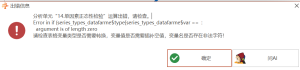
Error in if (series_types_datafarme$type[series_types_datafarme$var == : argument is of length zero
如图,错误非常常见 报错原因:变量名有非法字符,没有其他的原因(所有的节点都有可能会报这个错误) 常见类型: (1)变量名有空格:Var 1,Var 2 (2)变量名有奇怪字符:Var*1,Var$1,var%1...
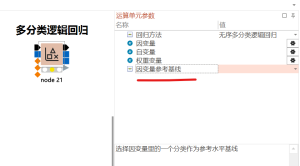
在回归分析中,如何修改分类变量的参照/参考/ref因子
在大多数回归分析,如线性回归,逻辑回归等分析中,分类变量往往需要指定一个参照因子(ref)进行分析,例如性别Gender的元素包含male和female,在通常情况下female往往会被作为ref处理,如果想...

环境缺失:Error in library(XXXXX)
报错原因:当看到有Error in library()这个错误的时候,说明有个别的R包环境缺失解决方法:(1)自行安装补充环境点程序-R终端打开R终端,输入install.packages('XXX')安装环境,缺什么包就写什...

Lasso回归-生存状态:Error in coxnet(xd, is.sparse, ix, jx, y, weights, offset, alpha, nobs, :NA/NaN/Inf in foreign function call (arg 4)
错误原因: 输入的变量组合导致Lasso模型拟合失败 解决方法: (1)Lasso回归的输入数据必须是数值,排除非法变量,例如含有字符串的变量 (2)如果不存在非法变量,则尝试换变量组合,或者修改...

Error in readRDS(model URl port) : ‘file’◆◆◆◆◆◆◆
错误原因:模型端口没有连接,灰色端口都是模型端口,带有模型端口的节点都可能出现这类错误.鼠标悬停端口上能看到输入输出的数据类型解决方法:连接灰色端口

孟德尔随机化分析如何把Beta值转成OR值
在孟德尔随机化分析中,通常使用Beta作为效应值,如果需要讲Beta转换被OR,则参考以下的计算公式OR = exp(Beta)Beta = ln(OR)CI置信区间:OR_lower = exp(Beta_lower)OR_upper = exp(Beta_upper...

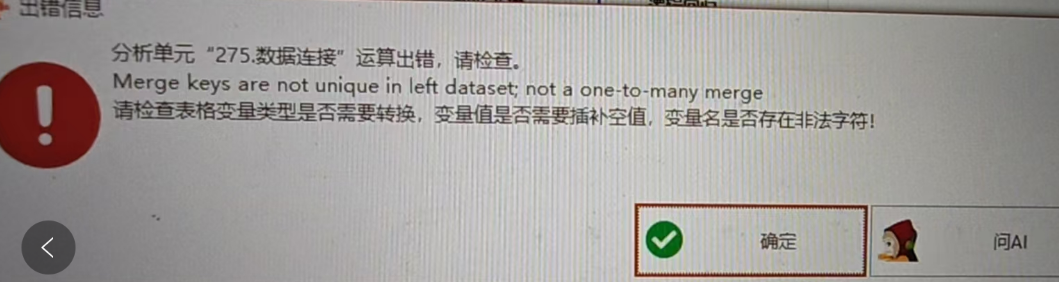
报错信息:Merge keys are not unique in left dataset, not a one-to-many merge
通常为左表的Key存在重复,应该使用m:m(多对多)的方法连接
孟德尔随机化分析如何增加样本的交集工具变量数
在孟德尔随机化分析中,获取样本间的交集工具变量是前提,如果交集工具变量数量过少甚至没有,则都无法成功执行后续的分析。增加交集工具变量的方法有:(1)扩大暴露样本SNP的P值,即扩大显著...
![Lapack routine dgesv: system is exactly singular: U[1,1]= 0-决策链社区论坛](https://bbs.statsape.com/wp-content/uploads/2025/04/20250413220533314-image-300x43.png)
Lapack routine dgesv: system is exactly singular: U[1,1]= 0
错误原因: 算法在计算过程中产生了奇异矩阵,导致无法计算,是参数,变量组合导致算法无法成功执行,可能的原因很多,例如变量间存在共线性很高的变量,样本量不足、用了分布类型非法的变量等...

敏感性分析-NHANES数据库挖掘讲解
【敏感性分析-冲击高分SCI】https://www.bilibili.com/video/BV1vUkMYhE8c?vd_source=816a05b7ef4ffb2e6c1d7318a736bced

Lasso回归-生存状态:Non-positive event times encountered; not permitted for Cox family
错误原因:因变量生存状态、生存时间的值必须大于0,不能等于0或者小于0解决方法:用筛选样本或者过滤表格节点,去除因变量不符合要求的样本
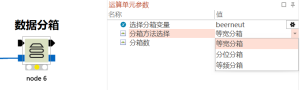
如何去除变量存在NA或者inf的样本
变量中的NA或者inf是无法参与计算的,通常需要在执行统计分析前将这些样本删除。 去除NA样本的方法: (1)筛选行空值的节点 (2)多条件过滤表格,使用notnull()的方法 删除inf样本 (1)筛选i...
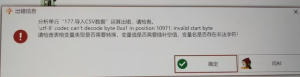
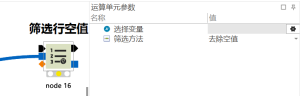
导入数据:’utf-8′ codec can’t decode byte 0xa1 in position 10971: invalid start byte
报错原因: 文件编码不是windows系统默认的,常常是因为Excel导出文件的时候选错了导出编码类型 解决方法: (1)Excel导出表格的时候选择正确的导出形式,避免选择CSV UTF-8 (2)如果方法一处...
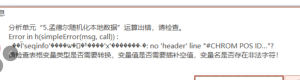
孟德尔随机化本地数据:Error in h(simpleError(msg, call)):◆◆’seqinfo”◆◆◆◆◆◆h◆◆◆◆’x”◆◆◆◆@◆◆.:no ‘header’ line “#CHROM POS ID..”?
报错原因:输入的GWAS遗传变异位点数据表格式非法,ieu数据库中收录的GWAS数据集很多存在这个问题,而且经常更新解决方案:(1)ieu官网重新下载目标编号的GWAS数据集(2)更换别的GWAS数据集

Error in glm.fit(x= c(1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,:NA/NaN/lnf in ‘y’
报错原因:通常为因变量的数值存在非数值的样本解决方法:检查因变量的值是否合法,对应的分布类型是否正确,将因变量非数值的样本转换成数值
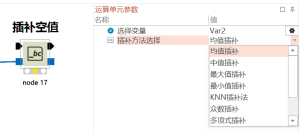
如何插补变量中的空值NA
变量中的NA即空值是无法参与计算的,在计算前建议先对NA值进行处理,对NA进行插补是常用的方法在决策链中有以下方法对NA进行插补:(1)空值插补节点,提供了多种方法(2)批量空值插补节点,在...


Error in paste(self$Code, self$ld, sep = ” “):cannot get ALTSTRING ELT during GC
报错原因:R语言自动清理内存失效解决方法:保存工程后重开软件

数据连接:Merge keys are not unique in either left or right dataset; not a one-to-one merge
报错原因:左表或者右表存在重复的id解决方法:(1)把匹配模式替换为1:m或者m:m(2)把左右表id去重复

潜类别混合增长模型:the leading minor of order 1 is not positive definite
报错原因:数据本身无法成功求导解决方法:(1)替换自变量(2)对自变量或者因变量进行归一化,插补等数据处理

NHANES读取Alpha:Passing ‘suffixes’ which cause duplicate columns {“WTDR2D X’, ‘DRDINT X, “DRABF X, “WTDRD1 x’ is not allowed
报错原因:读取节点选中的表格中,有个别表格间存在完全一样的变量,导致无法连接解决方法:报错信息中提示的变量名所在的表格单独提取后再与其他表格合并,例如WTDR2D这个变量名重复,找到这个...
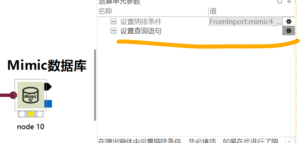
Mimic数据库:connection to server at “127.0.0.1”, port 33334 failed: Connection refused (0x0000274D/10061)Is the server runnina on that host and accepting TCP/P connections?
报错原因: Mimic数据库服务可能未开启 解决方法: (1)如果是刚开启软件,并刚打开的项目,则点击mimic查询数据库的参数设置按钮,初始化数据库服务 (2)以上方法无效的情况下...
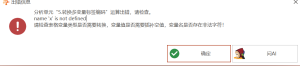
转换多变量标签编码:name ‘x’ is not defined
报错原因: 通常为写错变量名,如下图所示,只定义了x1和x2,“x”是一个没有定义的变量名 解决方法: 使用正确的变量名写命令,如上图的命令应该写成x1<=20 and x1>=3 此外,如下图所示...

没有模板如何知道节点的连接方法?
在决策链中,每个节点都有输入和输出的端口以传递数据分析的数据流,很多时候,即使没有模板流程,同样可以实现正确的连接(1)查看分析节点的输入端口信息,鼠标悬停在输入端口,查看端口数据...
转换多变量标签编码:invalid syntax. Perhaps you forgot a comma? (, line 1)
报错原因: (1)通常为逻辑连接符未加空格,此处应该写为x1<=20 and x2>=3 (2)字符串输入错误,入下图所示,55-59 years是一个字符串,应该写成x2=='55-59 years'

