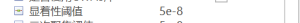首页
常见问题
操作技巧
数据库
NHANES
Mimic
PIC
SicDB
Charls
GDB
数据处理
数据导入
拼接表格(数据连接/合并)
基础统计
高级统计
机器学习
Python-机器学习(SciKit Learn)
R语言机器学习(MLR3)
专题探讨
生物信息学专题
随机对照实验专题
临床实验队列专题
真实世界研究
官网链接
决策链官网
决策链网页版
决策链 Wiki
发布
发布文章
创建话题
创建版块
发布帖子
登录
注册
找回密码
首页
常见问题
操作技巧
数据库
NHANES
Mimic
PIC
SicDB
Charls
GDB
数据处理
数据导入
拼接表格(数据连接/合并)
基础统计
高级统计
机器学习
Python-机器学习(SciKit Learn)
R语言机器学习(MLR3)
专题探讨
生物信息学专题
随机对照实验专题
临床实验队列专题
真实世界研究
官网链接
决策链官网
决策链网页版
决策链 Wiki
登录
注册
找回密码
4.3W+
2830
7
更多资料
搜索内容
空鱼O
浙江
管理员
这家伙很懒,什么都没有写...
关注
私信
关注Bilibili官方视频号获取更多教程
进入决策链官网获取更多信息
关注决策链 (DecisionLinnc) 公众号及视频号快速获取图文教程
进入决策链Wiki获取官方使用指南
文章
185
收藏
0
评论
1
版块
0
帖子
0
粉丝
7
NR曲线图:Error in findrow(fit, times, extend) : no points selected for one or more curves, consider using the extend argument
常见问题
1年前
0
136
9
选择变量:[‘subject_id’, ‘stay_id’] not in index
常见问题
# 选择变量
1年前
0
134
6
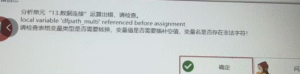
数据连接:local variable ‘dfpath multi’ referenced before assignment
常见问题
# 数据连接
1年前
0
109
12
逻辑回归经典列线图:Error in lims[[i]]:subscript out of bounds.
常见问题
11个月前
0
219
7
None of the stratifying variables have 2+ valid levels
常见问题
# 变量非法
1年前
0
198
8
=", ">"), ret.second(split_index), : Unknown decision_type-决策链社区论坛" class="lazyload fit-cover radius8">
Error in ifelse(decision_type %in% c(“>=”, “>”), ret.second(split_index), : Unknown decision_type
常见问题
1年前
0
161
5
多分类逻辑回归:Error in relevel.factor(WD[, var dependent],ref= dep ref) :’ref’eiiee
常见问题
# 多分类逻辑回归
1年前
0
122
7
调查设计统计分析结果没有P值怎么办
操作技巧
# 调查设计
1年前
0
182
6
面板数据效应模型:Error in `.rowNamesDF<-`(x, value = value) : ���������ظ���'row.names'
常见问题
# 面板数据效应模型
1年前
0
112
10
孟德尔随机化本地数据:Error: scanVcf: ‘R_Realloc’ could not re-allocate memory(87960856 bytes)
常见问题
# 孟德尔随机化本地数据
12个月前
0
188
10
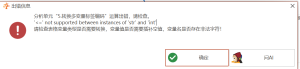
转换多变量标签编码:’<=' not supported between instances of 'str' and 'int'
常见问题
# 转换多变量标签编码
1年前
0
114
8
COX回归PH检验:Error in gzfile(file,”rb”): cannot open the connection
常见问题
# PH检验
1年前
0
124
11
贝叶斯核机回归模型:Error in checkSymmetricPositiveDefinite(H, name =”H”): H must be positive definite
常见问题
# 贝叶斯核机回归模型
1年前
0
112
13
NHANES读取Alpha:E:\NHANES\NHANESW2007-2008\Examination\bmx e.xpt表中缺少SEQN列!不能和其他表进行联合查询,你可以尝试单是名独提取此数据集。
常见问题
# NHANES读取
1年前
0
204
13
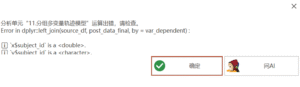
分组多变量轨迹模型:Error in dplyr:left join(source_df, post data final, by = var dependent) : x$subject id`is a
. v$subiect id`is a
.
常见问题
# 分组多变量轨迹模型
1年前
0
113
9
聚合表格:’NoneType’ object is not subscriptable
常见问题
# 聚合表格
11个月前
0
98
11
Error in glm.fit(x= c(1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,:NA/NaN/lnf in ‘y’
常见问题
11个月前
0
311
10
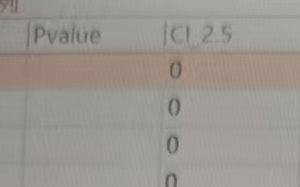
多因素竞争风险模型:Error in cmprsk::crr(WD[, var timel, WD[, var status], WD[, var treatment]):NA/NaN/nf in foreign function call (arg 4)
常见问题
# 多因素竞争风险模型
1年前
0
159
5
Error in if (whether cali == TRUE) {: argument is of length zero
常见问题
12个月前
0
184
12
Invalid argument: Unable to create new file for writing (it does not exist already). Do you have permission to write here, is there space on the disk and does the path exist?
常见问题
1年前
0
181
13
潜类别混合增长模型:the leading minor of order 1 is not positive definite
常见问题
# 潜类别混合增长模型
1年前
0
301
10
限制性立方样条曲线预测图:Error in geom line(size =as.numeric(ph$gdp(“geom smooth size”)), color = ph$gdp(“geom smooth color”), : iError occurred in the 1st layer.Caused by error in ph$gdp :! $ operator is invalid for atomicvectors
常见问题
11个月前
0
183
7
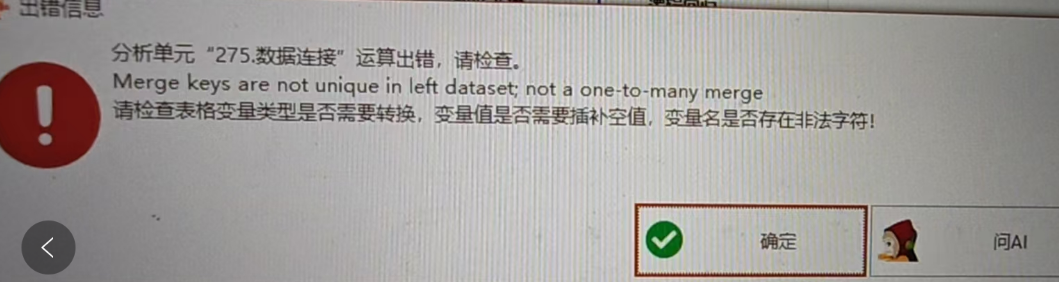
报错信息:Merge keys are not unique in left dataset, not a one-to-many merge
常见问题
# 参数错误
1年前
0
271
8
孟德尔随机化分析如何把Beta值转成OR值
生物信息学专题
# 孟德尔随机化
1年前
0
405
12
Cannot implicitly convert type ‘Python.Runtime.PyObject’ to ‘string[]’
常见问题
# 数据读取
1年前
0
100
10
多分类Rcs曲线图:data.frame(x=median x data,y= max up data, label =finally text data): ⧫⧫⧫⧫⧫⧫ζ@⧫⧫⧫⧫⧫⧫:2,0
常见问题
# 多分类Rcs曲线图
1年前
0
105
9
单因素亚组GLM回归:Error in purrr:map(var subgroups, ~TableSubgroupGLM(formula, var subqroup = . Caused by error in `TableSubqroupGLM()`: ! Please input correct subqroup variable
常见问题
# 单因素亚组GLM回归
1年前
0
192
9
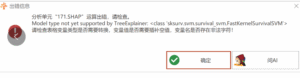
SHAP:Model type not yet supported by TreeExplainer:
常见问题
# SHAP
12个月前
0
240
8
孟德尔随机化分析如何增加样本的交集工具变量数
操作技巧
# 孟德尔随机化分析
1年前
0
369
10
Mimic数据提取:Exception while reading from stream
常见问题
# Mimic数据库
1年前
0
281
5
加载更多
发布文章
创建话题
创建版块
发布帖子
在手机上浏览此页面
登录
没有账号?立即注册
用户名或邮箱
登录密码
记住登录
找回密码
登录
注册
已有账号,立即登录
设置用户名
设置密码
重复密码
注册



![选择变量:['subject_id', 'stay_id'] not in index-决策链社区论坛](https://bbs.statsape.com/wp-content/uploads/2025/05/20250525205725654-image-300x68.png)
![逻辑回归经典列线图:Error in lims[[i]]:subscript out of bounds.-决策链社区论坛](https://bbs.statsape.com/wp-content/uploads/2025/08/20250821154610685-image-300x67.png)

 =", ">"), ret.second(split_index), :
Unknown decision_type-决策链社区论坛" class="lazyload fit-cover radius8">
=", ">"), ret.second(split_index), :
Unknown decision_type-决策链社区论坛" class="lazyload fit-cover radius8">![多分类逻辑回归:Error in relevel.factor(WD[, var dependent],ref= dep ref) :'ref'eiiee-决策链社区论坛](https://bbs.statsape.com/wp-content/uploads/2025/04/20250425215206746-image-300x55.png)







![多因素竞争风险模型:Error in cmprsk::crr(WD[, var timel, WD[, var status], WD[, var treatment]):NA/NaN/nf in foreign function call (arg 4)-决策链社区论坛](https://bbs.statsape.com/wp-content/uploads/2025/04/20250423204955500-image-300x46.png)





![Cannot implicitly convert type 'Python.Runtime.PyObject' to 'string[]'-决策链社区论坛](https://bbs.statsape.com/wp-content/uploads/2025/04/20250426134851368-image-300x109.png)