首页
常见问题
操作技巧
数据库
NHANES
Mimic
PIC
SicDB
Charls
GDB
数据处理
数据导入
拼接表格(数据连接/合并)
基础统计
高级统计
机器学习
Python-机器学习(SciKit Learn)
R语言机器学习(MLR3)
专题探讨
生物信息学专题
随机对照实验专题
临床实验队列专题
真实世界研究
官网链接
决策链官网
决策链网页版
决策链 Wiki
发布
发布文章
创建话题
创建版块
发布帖子
登录
注册
找回密码
首页
常见问题
操作技巧
数据库
NHANES
Mimic
PIC
SicDB
Charls
GDB
数据处理
数据导入
拼接表格(数据连接/合并)
基础统计
高级统计
机器学习
Python-机器学习(SciKit Learn)
R语言机器学习(MLR3)
专题探讨
生物信息学专题
随机对照实验专题
临床实验队列专题
真实世界研究
官网链接
决策链官网
决策链网页版
决策链 Wiki
登录
注册
找回密码
4.3W+
2830
7
更多资料
搜索内容
空鱼O
浙江
管理员
这家伙很懒,什么都没有写...
关注
私信
关注Bilibili官方视频号获取更多教程
进入决策链官网获取更多信息
关注决策链 (DecisionLinnc) 公众号及视频号快速获取图文教程
进入决策链Wiki获取官方使用指南
文章
185
收藏
0
评论
1
版块
0
帖子
0
粉丝
7
检查发现以下错误,请检查节点:[3.导入TSV数据 Plus]’ClassType
常见问题
1年前
0
216
13
逻辑回归经典列线图:Error in lims[[i]]:subscript out of bounds.
常见问题
10个月前
0
215
7
没有模板如何知道节点的连接方法?
操作技巧
# 节点连接
1年前
0
215
7
限制性立方样条:Error: The number of knots must be strictly between 3 and 7.
常见问题
# 限制性立方样条
1年前
0
213
11
转换多变量标签编码:invalid entry 0 in condlist: should be boolean ndarray
常见问题
# 转换多变量标签编码
1年前
0
211
8
转换多变量标签编码:name ‘x’ is not defined
常见问题
# 转换多变量标签编码
1年前
0
210
15
NHANES读取Alpha:Passing ‘suffixes’ which cause duplicate columns {“WTDR2D X’, ‘DRDINT X, “DRABF X, “WTDRD1 x’ is not allowed
常见问题
# NHANES读取Alpha
1年前
0
208
16
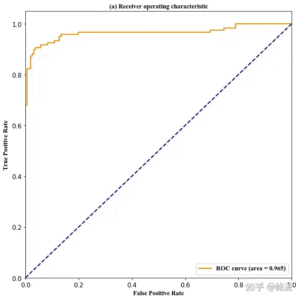
为什么ROC曲线是锯齿状的?
机器学习
# ROC曲线
11个月前
0
206
15
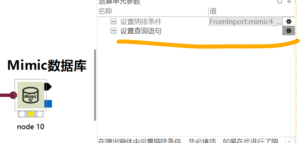
Mimic数据库:connection to server at “127.0.0.1”, port 33334 failed: Connection refused (0x0000274D/10061)Is the server runnina on that host and accepting TCP/P connections?
常见问题
# Mimic数据库
11个月前
0
206
10
自变量共线性筛查VIF:使用相关分析检查绝对相关的变量,去除相关系数为1的其中一个变量
常见问题
# 自变量共线性筛查VIF
11个月前
0
202
7
NHANES读取Alpha:E:\NHANES\NHANESW2007-2008\Examination\bmx e.xpt表中缺少SEQN列!不能和其他表进行联合查询,你可以尝试单是名独提取此数据集。
常见问题
# NHANES读取
1年前
0
200
13
孟德尔随机化:Error in if (nrow(d)== 0) return(NULL) : argument is of length zero
常见问题
# 孟德尔随机化
11个月前
0
199
8
SHAP解释器SE:Error in permshap.default(model rr, X= train set, feature names = xvars, : Permutation SHAP only supported for up to 14 features
常见问题
# SHAP解释器SE
10个月前
0
198
13
孟德尔随机化本地数据:Error in (function (classes,fdef, mtable): k'”NULL”
常见问题
# 孟德尔随机化本地数据
1年前
0
195
11
Error in paste(self$Code, self$ld, sep = ” “):cannot get ALTSTRING ELT during GC
常见问题
1年前
0
193
15
数据分析基线描述:Error in data.frame(Var = c(var num, var cate),ld = c(continuous rowid.:◆◆◆ζ↔◆◆◆◆◆◆:14 15
常见问题
# 数据分析基线描述
1年前
0
192
12
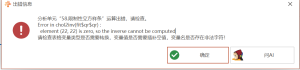
限制性立方样条:Error in chol2inv(fit$qr$qr) : element (22, 22) is zero, so the inverse cannot be computed
常见问题
# 限制性立方样条
1年前
0
191
6
单因素亚组GLM回归:Error in purrr:map(var subgroups, ~TableSubgroupGLM(formula, var subqroup = . Caused by error in `TableSubqroupGLM()`: ! Please input correct subqroup variable
常见问题
# 单因素亚组GLM回归
1年前
0
189
9
数据分析描述统计:Error in`[.data.frame`(WD,,i):◆◆◆◆w◆◆◆◆◆
常见问题
# 数据分析描述统计
1年前
0
187
9
聚合表格:JAVA GATEWAY_EXITED] Java gateway process exited before sending its port number
常见问题
# 聚合表格
11个月前
0
186
5
数据分箱:Bin edges must be unique: index([0.15, 0.19, 0.19, 0.22, 17.35], dtype=’float64′, name=’LBXlHG”)You can drop duplicate edaes by settina the ‘duplicates’ kwara
常见问题
# 数据分箱
1年前
0
185
10
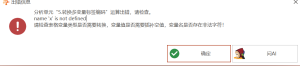
转换多变量标签编码:invalid character ‘>'(U+FF1E)(
, line 1)
常见问题
# 转换多变量标签编码
1年前
0
185
11
多重插补:Error in strsplit(var other raw,”,”);non-character argument
常见问题
# 多重插补
1年前
0
184
6
多条件过滤表格:Can only use .str accessor with string values!
常见问题
# 多条件过滤表格
1年前
0
184
6
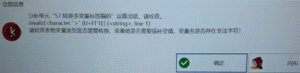
限制性立方样条:Error in which(sapply(var rsc, function(x)x== var predict))argument to ‘which’ is not logical
常见问题
# 限制性立方样条
1年前
0
184
13
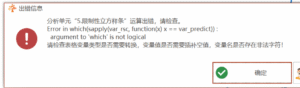
None of the stratifying variables have 2+ valid levels
常见问题
# 变量非法
1年前
0
183
8
限制性立方样条曲线预测图:Error in geom line(size =as.numeric(ph$gdp(“geom smooth size”)), color = ph$gdp(“geom smooth color”), : iError occurred in the 1st layer.Caused by error in ph$gdp :! $ operator is invalid for atomicvectors
常见问题
10个月前
0
183
7
为什么机器学习交叉验证/自助法的流程只有一个Test的分析结果
常见问题
# 机器学习
# 交叉验证
# 自助法
1年前
0
183
6
出现应用程序未处理的异常:OutOfMemoryException / Out of memory
常见问题
# 内存
1年前
0
182
7
潜类别混合增长模型:Error in gridsearch(rep=50,maxiter=10,minit = model, hlme(as.formula(fml),: The model minit did not converge.
常见问题
1年前
0
182
9
加载更多
发布文章
创建话题
创建版块
发布帖子
在手机上浏览此页面
登录
没有账号?立即注册
用户名或邮箱
登录密码
记住登录
找回密码
登录
注册
已有账号,立即登录
设置用户名
设置密码
重复密码
注册


![检查发现以下错误,请检查节点:[3.导入TSV数据 Plus]'ClassType-决策链社区论坛](https://bbs.statsape.com/wp-content/uploads/2025/06/20250603204628490-image-300x130.png)
![逻辑回归经典列线图:Error in lims[[i]]:subscript out of bounds.-决策链社区论坛](https://bbs.statsape.com/wp-content/uploads/2025/08/20250821154610685-image-300x67.png)













![聚合表格:JAVA GATEWAY_EXITED] Java gateway process exited before sending its port number-决策链社区论坛](https://bbs.statsape.com/wp-content/uploads/2025/04/20250413162853978-image-300x44.png)
![数据分箱:Bin edges must be unique: index([0.15, 0.19, 0.19, 0.22, 17.35], dtype='float64', name='LBXlHG](https://bbs.statsape.com/wp-content/uploads/2025/05/20250513211750897-image-300x76.png)