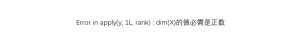首页
常见问题
操作技巧
数据库
NHANES
Mimic
PIC
SicDB
Charls
GDB
数据处理
数据导入
拼接表格(数据连接/合并)
基础统计
高级统计
机器学习
Python-机器学习(SciKit Learn)
R语言机器学习(MLR3)
专题探讨
生物信息学专题
随机对照实验专题
临床实验队列专题
真实世界研究
官网链接
决策链官网
决策链网页版
决策链 Wiki
发布
发布文章
创建话题
创建版块
发布帖子
登录
注册
找回密码
首页
常见问题
操作技巧
数据库
NHANES
Mimic
PIC
SicDB
Charls
GDB
数据处理
数据导入
拼接表格(数据连接/合并)
基础统计
高级统计
机器学习
Python-机器学习(SciKit Learn)
R语言机器学习(MLR3)
专题探讨
生物信息学专题
随机对照实验专题
临床实验队列专题
真实世界研究
官网链接
决策链官网
决策链网页版
决策链 Wiki
登录
注册
找回密码
19.4W+
2.8W+
2
更多资料
搜索内容
里里里里卡42
决策链编辑
浙江
管理员
这家伙很懒,什么都没有写...
关注
私信
关注Bilibili官方视频号获取更多教程
进入决策链官网获取更多信息
关注决策链 (DecisionLinnc) 公众号及视频号快速获取图文教程
进入决策链Wiki获取官方使用指南
文章
175
收藏
0
评论
0
版块
0
帖子
0
粉丝
2
发布
175
排序
最新发布
最近更新
最多查看
最多点赞
最多回复
最多收藏
销售数量
Error in friedman.test.default(mf[[1L]], mf[[2L]], mf[[3L]]) :不是非折疊完全区组设计
常见问题
# Friedman检验
1年前
0
108
11
Error in coxph(formula = Surv(rep(1, 119L), case) ~ alcohol + rubber + :No (non-missing) observations
常见问题
# 条件逻辑回归
1年前
0
83
13
Error in array(x, c(length(x), 1L), if (!is.null(names(x))) list(names(x), :’data’ must be of a vector type, was ‘NULL’
常见问题
# Meta剂量效应分析
1年前
0
123
12
该组数据无法绘制统计表
常见问题
# KM生存曲线
1年前
0
118
5
Error in gbm.unify(model, data):Models built on data with categorical features are not supported – please encode them before training.
常见问题
# SHAP解释器SE
1年前
0
216
6
使用字符串拆分和字符串截取进行字符串处理
操作技巧
# 字符串拆分
# 字符串截取
11个月前
0
93
6
Error in model.frame.default(Terms, newdata, na.action = na.action, xlev = object$xlevels) :因子pathology_T_stage里出现了新的层次t1a
常见问题
# 中介效应
1年前
0
140
5
Error in anova.svyglm(model_one, model_two, test = “Chisq”) :models not nested
常见问题
# 似然比检验
1年前
0
110
6
Error in ssum[2,,1]:subscript out of bounds
常见问题
# 生存分析校准曲线
1年前
0
150
6
Error in if (class(model)[1] != “glm” & class(model)[2] != “lm” & class(model)[1] != :missing value where TRUE/FALSE needed
常见问题
# 相对超额风险分析
1年前
0
95
9
【新手必看】软件快速上手贴(持续更新)
操作技巧
1年前
0
1.4W+
2102
用选择变量剔除大量无用的变量
操作技巧
# 选择变量
11个月前
0
117
13
分析单元“143.Lasso回归-二项式 Plus”运算出错,请检查.Error in if (series types datafarmestypelseries types datafarmesvar == :arqument is of length zero请检查表格变量类型是否符需要转换,变量值是否需要插补空值,变量名是否存在非法字符!
常见问题
# Lasso回归-二项式
1年前
0
189
6
Error in dimnames(x) <- dn :length of 'dimnames' [1] not equal to array extent
常见问题
# Ridit分析
1年前
0
190
7
Error: Rank deficient model matrix; insufficient data to estimate full model.Model coefficient(s) estimated as NA: cyl2:am1Likely empty cells in between-subjects design (i.e., bad data structure).
常见问题
# Two-Way-ANOVA
1年前
0
127
7
Error in lme.formula(as.formula(fml), data = WD, random = as.formula(fml_rand)) :fewer observations than random effects in all level 1 groups
常见问题
# 线性混合模型
1年前
0
131
8
运行出错,看不懂错误代码怎么办?
操作技巧
1年前
0
132
15
Error in geese.fit(xx, yy, id, offset, soffset, w, waves = waves, zsca, :nrow(zsca) and length(y) not match
常见问题
# 广义估计方程
1年前
0
196
10
运算因错误中止,原因:Error in data.frame(…, check.names = FALSE) :参数值意味着不同的行数: 546, 528
常见问题
# 调查设计加权嵌套-回归分析
1年前
0
138
8
Error in dosresmeta.fit(X[v != 0, , drop = FALSE], Z[v != 0, , drop = FALSE], :A two-stage approach requires that each study provides at least p non-referent obs (p is the number of columns of the design matrix X)
常见问题
# Meta剂量效应分析
1年前
0
81
14
Error in UseMethod(“predict”) :no applicable method for ‘predict’ applied to an object of class “c(‘gamm’, ‘list’)”
常见问题
# 回归模型预测
1年前
0
126
11
Error: You should have at least two distinct break values. Value cannot be null. (Parameter ‘s’)
常见问题
# SHAP解释器SE
1年前
0
168
14
插补:多重插补与插补空值
常见问题
# 多重插补
# 插补空值
11个月前
0
147
7
Error in binom.test(sum(mydata1[, var_input[i]] < mydata2[, var_input[i]]), :'n'必需是大于等于'x'的正整数
常见问题
1年前
0
137
7
Error in str2lang(x) : :2:0: unexpected end of input1: ~^请检查表格变量类型是否符需要转换,变量值是否需要插补空值,变量名是否存在非法字符!
常见问题
# 似然比检验
1年前
0
179
9
Error in cbind(reliability[, c(“index.orig”, “training”, “test”), drop = FALSE], :number of rows of matrices must match (see arg 6)
常见问题
# 生存分析校准曲线
# 机器学习生存绘图
1年前
0
105
12
Error in quadprog::solve.QP(C, -d, t(H), f, meq = meq) :constraints are inconsistent, no solution!
常见问题
# 机器学习生存模型SE
1年前
0
104
5
安装软件教程
操作技巧
1年前
0
275
8
Error in $<-.data.frame(*tmp*, "mfit", value = c(1 = -11.7386871143257, :替换数据里有319行,但数据有423请检查表格变量类型是否符需要转换,变量值是否需要插补空值,变量名是否存在非法字符!
常见问题
# 平滑曲线拟合
1年前
0
104
8
Error in apply(y, 1L, rank) : dim(X)的值必需是正数
常见问题
# Friedman检验
1年前
0
109
13
加载更多
发布文章
创建话题
创建版块
发布帖子
在手机上浏览此页面
登录
没有账号?立即注册
用户名或邮箱
登录密码
记住登录
找回密码
登录
注册
已有账号,立即登录
设置用户名
设置密码
重复密码
注册


![Error in friedman.test.default(mf[[1L]], mf[[2L]], mf[[3L]]) :不是非折疊完全区组设计-决策链社区论坛](https://bbs.statsape.com/wp-content/uploads/2025/04/20250414120154982-4-300x50.jpg)







![Error in ssum[2,,1]:subscript out of bounds-决策链社区论坛](https://bbs.statsape.com/wp-content/uploads/2025/04/20250415165054322-81-300x53.jpg)
![Error in if (class(model)[1] !=](https://bbs.statsape.com/wp-content/uploads/2025/04/20250416121043426-114-300x53.jpg)

![Error in dimnames(x) <- dn :length of 'dimnames' [1] not equal to array extent-决策链社区论坛](https://bbs.statsape.com/wp-content/uploads/2025/04/20250415134026868-59-300x54.jpg)




![Error in dosresmeta.fit(X[v != 0, , drop = FALSE], Z[v != 0, , drop = FALSE], :A two-stage approach requires that each study provides at least p non-referent obs (p is the number of columns of the design matrix X)-决策链社区论坛](https://bbs.statsape.com/wp-content/uploads/2025/04/20250415163020872-70-300x52.jpg)


![Error in binom.test(sum(mydata1[, var_input[i]] < mydata2[, var_input[i]]), :'n'必需是大于等于'x'的正整数-决策链社区论坛](https://bbs.statsape.com/wp-content/uploads/2025/04/20250414152122184-16-300x54.jpg)