首页
常见问题
操作技巧
数据库
NHANES
Mimic
PIC
SicDB
Charls
GDB
数据处理
数据导入
拼接表格(数据连接/合并)
基础统计
高级统计
机器学习
Python-机器学习(SciKit Learn)
R语言机器学习(MLR3)
专题探讨
生物信息学专题
随机对照实验专题
临床实验队列专题
真实世界研究
官网链接
决策链官网
决策链网页版
决策链 Wiki
发布
发布文章
创建话题
创建版块
发布帖子
登录
注册
找回密码
首页
常见问题
操作技巧
数据库
NHANES
Mimic
PIC
SicDB
Charls
GDB
数据处理
数据导入
拼接表格(数据连接/合并)
基础统计
高级统计
机器学习
Python-机器学习(SciKit Learn)
R语言机器学习(MLR3)
专题探讨
生物信息学专题
随机对照实验专题
临床实验队列专题
真实世界研究
官网链接
决策链官网
决策链网页版
决策链 Wiki
登录
注册
找回密码
4.3W+
2830
7
更多资料
搜索内容
空鱼O
浙江
管理员
这家伙很懒,什么都没有写...
关注
私信
关注Bilibili官方视频号获取更多教程
进入决策链官网获取更多信息
关注决策链 (DecisionLinnc) 公众号及视频号快速获取图文教程
进入决策链Wiki获取官方使用指南
文章
185
收藏
0
评论
1
版块
0
帖子
0
粉丝
7
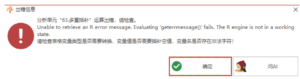
多重插补:Unable to retrieve an R error message. Evaluating ‘geterrmessage0’ fails, The R engine is not in a working state.
常见问题
# 多重插补
11个月前
0
145
11
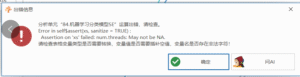
机器学习分类模型SE:Error in self$assert(xs, sanitize = TRUE) :Assertion on ‘xs’ failed: num.threads: May not be NA
常见问题
# 机器学习分类模型SE
11个月前
0
106
12
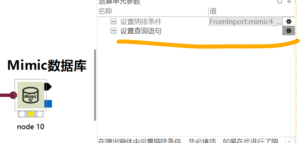
Mimic数据库:connection to server at “127.0.0.1”, port 33334 failed: Connection refused (0x0000274D/10061)Is the server runnina on that host and accepting TCP/P connections?
常见问题
# Mimic数据库
11个月前
0
206
10
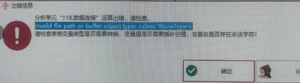
数据连接:invalid file path or buffer object type:
常见问题
# 数据连接
11个月前
0
156
8
生存分析截断值搜索:Error in Summary.factor(c(2L,1L,1L,2L,1L,2L,2L,2L,1L,1L,1L,:”range’not meaningful for factors
常见问题
# 生存分析截断值搜索
11个月前
0
142
14
分类预测:Feature shape mismatch, expected: 20, got 16
常见问题
# 分类预测
11个月前
0
109
5
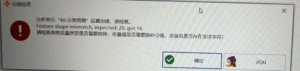
聚合表格:JAVA GATEWAY_EXITED] Java gateway process exited before sending its port number
常见问题
# 聚合表格
11个月前
0
186
5
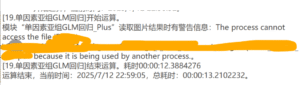
because it is being used by another process
常见问题
11个月前
0
108
12
高级变量运算:unsupported operand type(s) for -:’str’ and ‘str’
常见问题
# 高级变量运算
11个月前
0
150
12
潜类别分析:Error in names(x)<- value: ‘names’ attribute [4] must be the same length as the vector [0].
常见问题
# 潜类别分析
11个月前
0
151
9
数据连接:Merge keys are not unique in either left or right dataset; not a one-to-one merge
常见问题
# 数据连接
11个月前
0
247
7
逻辑回归:Error in run(param_manager) : object ‘source external’ not found
常见问题
# 逻辑回归
11个月前
0
178
12
潜类别混合增长模型:the leading minor of order 1 is not positive definite
常见问题
# 潜类别混合增长模型
11个月前
0
298
10
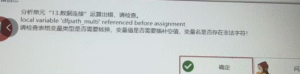
数据连接:local variable ‘dfpath multi’ referenced before assignment
常见问题
# 数据连接
11个月前
0
109
12
多因素COX回归:Error in path.expand(new):invalid ‘path’ argument
常见问题
# 多因素COX回归
11个月前
0
109
11
自变量共线性筛查VIF:使用相关分析检查绝对相关的变量,去除相关系数为1的其中一个变量
常见问题
# 自变量共线性筛查VIF
11个月前
0
202
7
机器学习多模型绘图SE:Error in str2lang(x):
:1:2: unexpected input1:1_ ^
常见问题
# 机器学习多模型绘图SE
1年前
0
131
12
Lasso回归-泊松:negative responIses encountered: not permitted for Poisson family
常见问题
# Lasso回归-泊松
1年前
0
104
5
孟德尔多元表型数据转换后数据条目减少
生物信息学专题
# 孟德尔多元表型数据转换
1年前
0
112
10
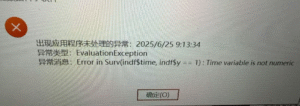
Error in Surv(indf$time, indf$y== 1): Time variable is not numeric
常见问题
1年前
0
152
15
分组多变量轨迹模型:Error in gbmt:gbmt(x.names = var independent, unit = var_dependent, time = var time,Variable ‘time’ must be either numeric or date
常见问题
# 分组多变量轨迹模型
1年前
0
223
13
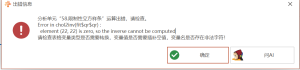
限制性立方样条:Error in chol2inv(fit$qr$qr) : element (22, 22) is zero, so the inverse cannot be computed
常见问题
# 限制性立方样条
1年前
0
191
6
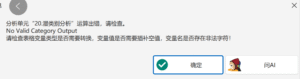
潜类别分析:No Valid Category Output
常见问题
# 潜类别分析
1年前
0
151
15
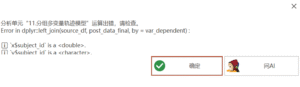
分组多变量轨迹模型:Error in dplyr:left join(source_df, post data final, by = var dependent) : x$subject id`is a
. v$subiect id`is a
.
常见问题
# 分组多变量轨迹模型
1年前
0
113
9
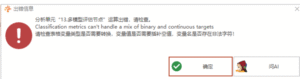
多模型评估节点:Classification metrics can’t handle a mix of binary and continuous targets
常见问题
# 多模型评估节点
1年前
0
134
5
分析单元“4.随机森林”运算出错,请检查。 INonel
常见问题
# 随机森林
1年前
0
110
5
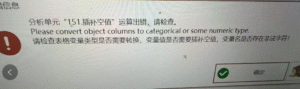
插补空值:Please convert object columns to categorical or some numeric type
常见问题
1年前
0
130
5
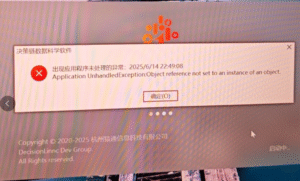
软件无法启动:Application UnhandledException:Object reference not set to an instance of an object
常见问题
1年前
0
109
6
SHAP:Error in .input_checks(object = object, X = X, baseline = baseline, S_inter = S_inter) : ‘X’ must be a matrix or data.frame
常见问题
# SHAP
1年前
0
151
6
RuntimeBinderException Cannot implicitly convert type ‘Python.Runtime.PyObject’ to ‘string[]’
常见问题
1年前
0
129
13
加载更多
发布文章
创建话题
创建版块
发布帖子
在手机上浏览此页面
登录
没有账号?立即注册
用户名或邮箱
登录密码
记住登录
找回密码
登录
注册
已有账号,立即登录
设置用户名
设置密码
重复密码
注册



![聚合表格:JAVA GATEWAY_EXITED] Java gateway process exited before sending its port number-决策链社区论坛](https://bbs.statsape.com/wp-content/uploads/2025/04/20250413162853978-image-300x44.png)

![潜类别分析:Error in names(x)<- value: 'names' attribute [4] must be the same length as the vector [0].-决策链社区论坛](https://bbs.statsape.com/wp-content/uploads/2025/06/20250623110239874-image-300x29.png)










![RuntimeBinderException
Cannot implicitly convert type 'Python.Runtime.PyObject' to 'string[]'-决策链社区论坛](https://bbs.statsape.com/wp-content/uploads/2025/06/20250614212041411-image-300x112.png)

