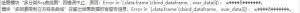首页
常见问题
操作技巧
数据库
NHANES
Mimic
PIC
SicDB
Charls
GDB
数据处理
数据导入
拼接表格(数据连接/合并)
基础统计
高级统计
机器学习
Python-机器学习(SciKit Learn)
R语言机器学习(MLR3)
专题探讨
生物信息学专题
随机对照实验专题
临床实验队列专题
真实世界研究
官网链接
决策链官网
决策链网页版
决策链 Wiki
发布
发布文章
创建话题
创建版块
发布帖子
登录
注册
找回密码
首页
常见问题
操作技巧
数据库
NHANES
Mimic
PIC
SicDB
Charls
GDB
数据处理
数据导入
拼接表格(数据连接/合并)
基础统计
高级统计
机器学习
Python-机器学习(SciKit Learn)
R语言机器学习(MLR3)
专题探讨
生物信息学专题
随机对照实验专题
临床实验队列专题
真实世界研究
官网链接
决策链官网
决策链网页版
决策链 Wiki
登录
注册
找回密码
4.3W+
2830
7
更多资料
搜索内容
空鱼O
浙江
管理员
这家伙很懒,什么都没有写...
关注
私信
关注Bilibili官方视频号获取更多教程
进入决策链官网获取更多信息
关注决策链 (DecisionLinnc) 公众号及视频号快速获取图文教程
进入决策链Wiki获取官方使用指南
文章
185
收藏
0
评论
1
版块
0
帖子
0
粉丝
7
敏感性分析-NHANES数据库挖掘讲解
临床实验队列专题
# 敏感性分析
1年前
0
301
11
Error in purrr:map(var subgroups, ~TableSubgroupGLM(formula, var subgroup =. Caused by error in`.svycheck(): !..2 used in an incorrect context, no .. to look in
常见问题
1年前
0
161
5
XGBoost:Invalid classes inferred from unique values of `y. Expected: [0 1], got [1 2]。
常见问题
# XGBoost
1年前
0
225
11
多重插补:Unable to retrieve an R error message. Evaluating ‘geterrmessage0’ fails, The R engine is not in a working state.
常见问题
# 多重插补
12个月前
0
145
11
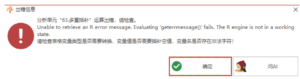
转换多变量标签编码:invalid syntax. Perhaps you forgot a comma? (
, line 1)
常见问题
# 转换多变量标签编码
12个月前
0
221
8
分类预测:‘DecisionTreeRegressor’ object has no attribute ‘predict proba’
常见问题
# 分类预测
1年前
0
121
6
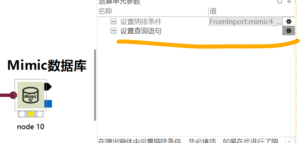
Mimic数据库:connection to server at “127.0.0.1”, port 33334 failed: Connection refused (0x0000274D/10061)Is the server runnina on that host and accepting TCP/P connections?
常见问题
# Mimic数据库
12个月前
0
208
10
转换多变量标签编码:invalid character ‘>'(U+FF1E)(
, line 1)
常见问题
# 转换多变量标签编码
1年前
0
189
11
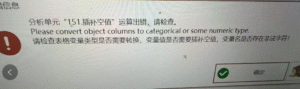
插补空值:Please convert object columns to categorical or some numeric type
常见问题
1年前
0
130
5
预测器SE:Error in model_rr$predict_newdata(newdata = newdata, task = tsk_wd) : attempt to apply non-function
常见问题
# 预测器SE
11个月前
0
181
7
筛选样本:根据输入的列名没有找到匹配的规范变量名
常见问题
1年前
0
172
9
转换多变量标签编码:The truth value of a Series is ambiguous. Use a.empty, a.bool(, a.item(, a.any( or a.all0).
常见问题
# 转换多变量标签编码
1年前
0
94
7
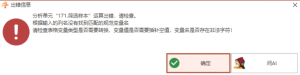
生存分析ROC图:Error in roc.default(response, predictors[, 1], …) : ‘response’ must have two levels
常见问题
1年前
0
165
14
高级变量运算:unsupported operand type(s) for -:’str’ and ‘str’
常见问题
# 高级变量运算
1年前
0
153
12
自变量共线性筛查VIF:使用相关分析检查绝对相关的变量,去除相关系数为1的其中一个变量
常见问题
# 自变量共线性筛查VIF
1年前
0
206
7
IDI和NRI:Error in if (pest$lDI > 0) {: missing value where TRUE/FALSE needed
常见问题
# IDI和NRI
11个月前
0
172
14
环境缺失:Error in library(XXXXX)
常见问题
# 环境缺失
1年前
0
323
7
数据任务器SE:Error in strsplit(pm$get para value(“positive”),”\s*”): non-character arqument
常见问题
# 数据任务器SE
1年前
0
125
11
高级变量运算:invalid decimal literal (
,line 1)
常见问题
1年前
0
144
11
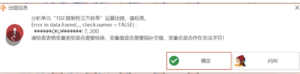
限制性立方样条:Error in data.frame(…. check.names = FALSE) :◆◆◆◆◆◆◆◆◆ 7, 200
常见问题
# 限制性立方样条
1年前
0
158
6
out of memoryDETAlL: Failed on request ofsize 19896550 in memory context Errorcontext
常见问题
12个月前
0
96
5
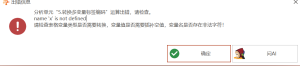
转换多变量标签编码:name ‘x’ is not defined
常见问题
# 转换多变量标签编码
1年前
0
217
15
数据连接:Unable to allocate XXX GiB for an array with shape (XXXXX) and data type float64.
常见问题
# 数据连接
1年前
0
175
6
多条件过滤表格:’>’ not supported between instances of str and int
常见问题
# 多条件过滤表格
1年前
0
69
9
数据分箱:Bin edges must be unique: index([0.15, 0.19, 0.19, 0.22, 17.35], dtype=’float64′, name=’LBXlHG”)You can drop duplicate edaes by settina the ‘duplicates’ kwara
常见问题
# 数据分箱
1年前
0
188
10
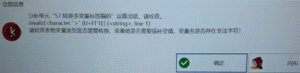
分析单元“4.随机森林”运算出错,请检查。 INonel
常见问题
# 随机森林
1年前
0
111
5
数据分析描述统计:Error in `[.data.frame`(upstream_df_sub, , var_cont) :ѡ����δ�������
常见问题
11个月前
0
237
7
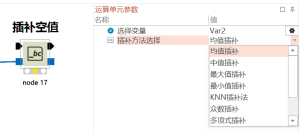
如何插补变量中的空值NA
操作技巧
# 空值插补
1年前
0
232
7
多分类Rcs曲线图:Error in’l,data.frame`(cbind dataframe,,xvar datal): wo00080000009。
常见问题
# 多分类Rcs曲线图
1年前
0
132
13
Cox_CiC曲线图:Error in decision_curve(formula_data, data = input_data, family = binomial(link = “logit”), : outcome variable is not binary (it does not take two unique values).
常见问题
1年前
0
129
10
加载更多
发布文章
创建话题
创建版块
发布帖子
在手机上浏览此页面
登录
没有账号?立即注册
用户名或邮箱
登录密码
记住登录
找回密码
登录
注册
已有账号,立即登录
设置用户名
设置密码
重复密码
注册




![XGBoost:Invalid classes inferred from unique values of `y. Expected: [0 1], got [1 2]。-决策链社区论坛](https://bbs.statsape.com/wp-content/uploads/2025/06/20250607142348511-image-300x69.png)

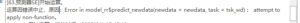

![生存分析ROC图:Error in roc.default(response, predictors[, 1], ...) : 'response' must have two levels-决策链社区论坛](https://bbs.statsape.com/wp-content/uploads/2025/05/20250501214346549-image-300x88.png)








![数据分箱:Bin edges must be unique: index([0.15, 0.19, 0.19, 0.22, 17.35], dtype='float64', name='LBXlHG](https://bbs.statsape.com/wp-content/uploads/2025/05/20250513211750897-image-300x76.png)